
Ready to make incident response your competitive advantage?
See how Uptime Labs builds provable, scalable incident response capability across your organisation.
1. Beyond “5 Whys”: A Better Way to Learn from Incidents
Penned by former incident responder & current CEO, Hamed Silatani, ‘Beyond 5 Whys’ offers a fair balance on where 5 Whys can assist root cause analysis and where it can actually limit incident response capabilities. Instead of repeatedly asking ‘why’, Hamed shows, with examples, how open-ended questions can lead to deeper exploration and avoid unintentional bias.
Key quote: “If the goal of post-incident reviews is learning, then “5 Whys” limits that learning by narrowing discovery, reinforcing biases, and preventing open exploration. By shifting to open-ended, reflective questions, we unlock more meaningful insights and systemic improvements.”
2. Is Fewer Incidents Always Good?

Imagine a graph of incident volume with the line going down. That’s the dream, right?
Or is it? Actually, incidents can be opportunities to build lasting organisational resilience, argues Hamed, in another practical and persuasive article.
Key quote: “Envisioning a future devoid of undesirable or unexpected events is appealing but unrealistic. Hidden within the premise of zero-incident attainability is the assumption that all possible eventualities within a complex system can be known, and ‘designed for’. Achieving zero incidents assumes complete foresight and design for all possible eventualities in complex systems. While system reliability can improve, resilience will always be tested by unforeseen surprises.”
3. What I Really Mean When I Say “Good Communication” in Incident Response
‘Better communication during incidents’ is an admirable yet ambiguous goal. Hamed breaks down what good communication looks like for different stakeholders, using real examples.
Key quote: “When these skills are properly understood and regularly practiced, incidents stop feeling like chaos. Instead, they become exactly what they should be — opportunities for learning, growth, and even a bit of team bonding.”
4. What Experts See That the Rest of Us Miss During Incidents

In one of our most ambitious posts, Hamed draws on the insights of Eric Dobbs, a Principal Incident Analyst, who observed two experienced responders tackle our incident simulations. Hamed compiles the nuances that were captured between the two responders and reflects on an idea that’s been recurring across many of our blog posts this year - how do you handle senior stakeholders who join an incident?
Key quote: “I learnt a new way of managing senior authorities that (unconsciously and with good intention) interfere with incident resolution. It’ll take me few more drills to try the technique until it becomes muscle memory – another tool in my toolbox of handling senior execs on incident bridge – that I can leverage during real-life incidents in the right context.”
5. Turning Non-Prod Incidents into Resilience-Building Opportunities
Joe, our CTO, shares a recent perspective on why non-production incidents are essential to building true resilience. Drawing on his firsthand experience during an incident, he illustrates how organisations can move beyond blame and create meaningful learning opportunities, offering a candid look at the thinking and decision-making that shape resilient systems.
Key quote: “Instead of asking, “Who is responsible?” focus on “What allowed this to happen?” Recognise that mistakes are often the result of flawed processes, unclear expectations, or inadequate safeguards, rather than individual negligence.”
6. Advice for First-Time Staff SREs
The step up to staff SRE can feel daunting - but if you’ve been promoted, you’ve been promoted for a reason. Karan Nagarajagowda is a former Staff SRE and shares all the advice a first-time Staff SRE needs to lead their team towards a more resilient future.
Key quote: “A Staff SRE needs deep horizontal knowledge – understanding how everything from data centres to application deployments connects. You don’t need full depth in every area, but you should grasp enough of each to make smart judgments.”
7. Your Brain on Incidents

Do you ever wonder what’s going on in your brain during incidents?
Stuart, our CPO, explores the psychological reality of incident response and the actions that can mitigate the negative effects of incidents. He also shares a painfully relatable (or relatably painful) anecdote from his first on-call experience.
Key quote: “Stress is not a universally bad thing. A little stress can (in some people) enhance focus, but incidents typically elicit enough stress simply by being time-critical, high-pressure, uncertain and ambiguous. Therefore, much of our energy is wisely directed towards modulating stress downwards.”
8. Resilience vs. Robustness

As much as both words connote ‘strength’ and ‘endurance’, they actually have very different meanings. Stuart uses an allegory to vividly illustrate the pitfalls of confusing the two key concepts. Resilience does not mean robustness, and organisations that treat resilience as a one-time achievement risk building brittle, inflexible systems.
Key quote: “Turns out, in my pursuit of a ‘robust’ tree, I’d inadvertently (some would say stupidly) stunted the tree’s ‘resilience’. The stakes that I deployed to help support the tree were indeed robust. But they also shared an attribute common to many robust systems: they were brittle. They provided plenty of support until a threshold was reached, upon which they failed suddenly and catastrophically.”
9. When Fast Flow Delivers A Real Blow: A PIR
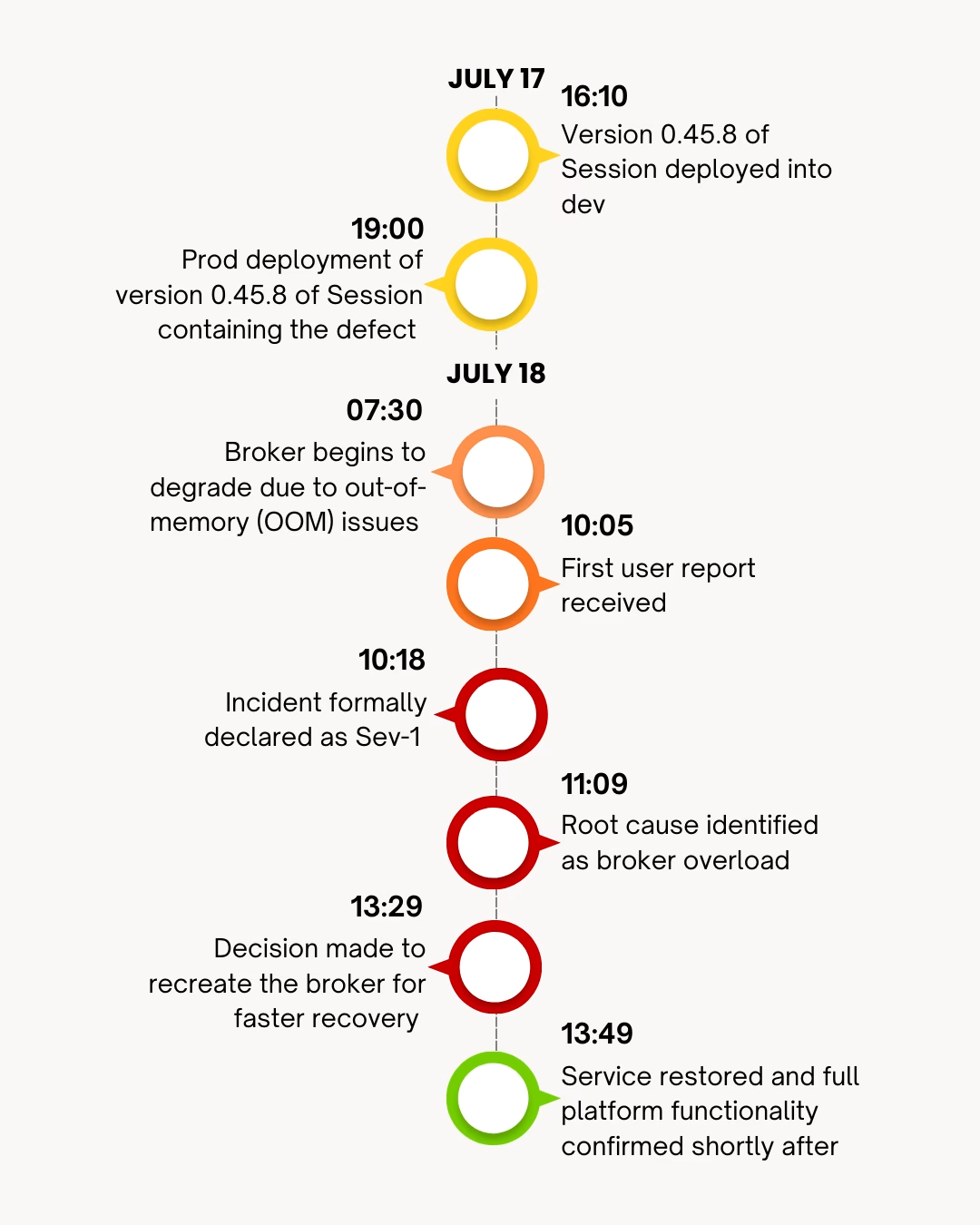
When we posted about this article on Reddit, we got a couple of comments asking, “What’s a PIR?” (FYI, we borrow Microsoft’s term to mean post-mortem). We autospied a particularly stressful incident from June, explaining how the 24 hours went down.
Joe imbues the article with technical detail, and uses it as an opportunity to explore a few of our key technical principles, such as ‘Progress over perfection’.
Key quote: “We also have a simple rule of thumb: key infrastructure components should soak in dev for at least a working day before release. In practice, we often soak them during core hours and then ship. With stronger monitoring and alerting now in place, we are more confident that if something slips through, we will be on it quickly.”
10. Who’s in Charge?
It should be a simple question, but during an incident, it can be unclear who’s flying the plane. Joe writes empathetically and practically about how to assume and hand over leadership when it matters the most. Follow his advice, and next time you experience an incident, you should be able to answer in a second, “Who’s in charge?”
Key quote: “Handovers are professional. Handovers prevent mistakes. But again: They must be explicit.
The team should always be able to answer the question “Who’s flying the plane?” within one second.”
We’ve had a great time writing these articles, and we hope that you’ve enjoyed reading them! If you’d like to contribute an article for the blog, you can reach our editor at charli@uptimelabs.io.
Happy New Year!
Sam Salter




