
Ready to make incident response your competitive advantage?
See how Uptime Labs builds provable, scalable incident response capability across your organisation.
Karan is our Senior Customer Success Engineer (focused on designing our library of incident simulations!). He was also SRE Team Lead at IG, as well as a Software Engineer at Tata and a Senior Software Engineer at Fidelity Investments.
The most dangerous thing I’ve seen in engineering isn’t a failed system. It’s a team that thinks their system can’t fail.
It’s not just about adding and adapting tooling. The leader who believes a new $30pp automation tool will resolve deep systemic issues is overlooking the most valuable resource already sitting inside their organisation: their people.
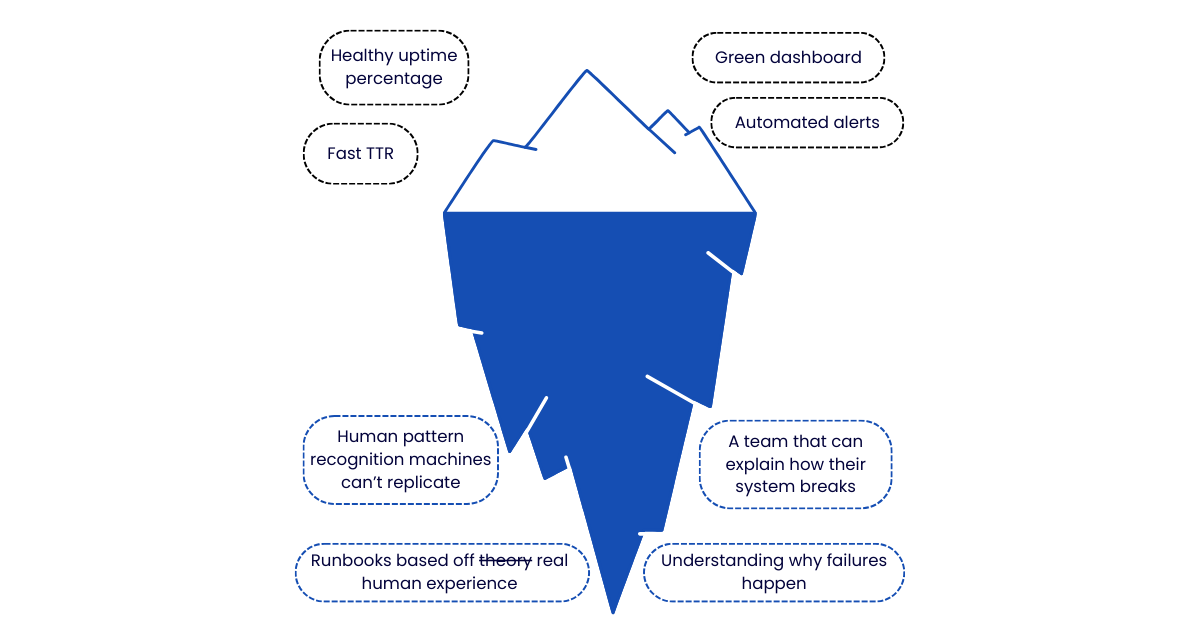
At Uptime Labs, we come back to the same principle repeatedly – the true source of resilience is people. Not because it’s a neat slogan, but because the evidence keeps pointing there. Below are five reasons why resilience can’t be automated away from people entirely – hope you enjoy.
1. Automation can sometimes hide failures rather than fixing them.
Green dashboards are comforting. They’re also potentially dangerous.
The teams that haven’t been tested often rely entirely on monitoring dashboards showing everything is green. But they’ve never seen their system behave under stress.
I’ve lived through two incidents that made this distinction crystal-clear.
The first: we had automated traffic draining from unhealthy application nodes. To us, it was sensible. Well-intentioned. And for a while, it worked – user availability stayed high. No outages. So the system looked rock solid.
What was happening beneath the surface was quite a different story. One node kept getting flagged as unhealthy due to database connection pool exhaustion – a real, unresolved bug.
Each time it was flagged, the load balancer quietly moved traffic elsewhere. The problem never surfaced as an incident. Instead, it silently reduced the cluster’s capacity.
The reckoning came during a high-volatility market event. Traffic spiked. The degraded cluster couldn’t cope. What had looked like resilience collapsed under load.
My second example is simpler – and arguably more common. We automated service restarts. Any time a node went down, the system brought it back. Uptime looked excellent. Everyone in the team was happy.
But buried in the logs, the service was restarting multiple times a day, driven by a memory leak. Nobody noticed until someone looked at restart frequency rather than just availability metrics.
Both cases had the same fix: add observability not just to outcomes, but to the signals the automation was acting on. Not just: is it up? But: why is it doing that?
In other words, automated recovery was hiding a recurring failure.
Meaning automation without feedback mechanisms doesn’t create resilient systems – it creates brittle ones, as both of these incidents showed
2. Tooling can’t replace human instinct.
Tools measure what they’re configured to measure. They’re less good at everything else.
We had an incident where application response times were climbing – but CPU, memory, and network metrics showed nothing unusual. Standard procedure: work through the stack layer by layer: Application – Infrastructure – Hardware – Storage.
One of my engineers skipped ahead, because he suspected disc IO because he’d seen similar behaviour before. So instead of looking at the application, he went straight to the storage layer.
He was right. A SAN storage controller had started throttling disk IO due to failing discs in the RAID group. The monitoring tools hadn’t flagged it clearly. Nothing in the runbook pointed there.
Pattern recognition – built from years of watching systems fail – led him straight to the source. The disc was replaced, the array was rebuilt, and performance returned to normal.
That gut feeling is purely based on symptoms, alerts and signals. It’s very difficult to build into a system. But it’s a necessary part of resilience, nonetheless. To quote Vanessa Huerta Granda at QCon, incidents make engineers.
3. Automation robs engineers of the chance to learn.
When automation handles remediation – restarting services, clearing queues, failing over nodes – it works. The symptom disappears and the alert clears.
But at the same time, so does the opportunity to deep dive into why it happened.
Think of it like a mechanic. Fix the engine one week, the fuel tank the next, the air filter the week after. Over time, you build an embodied understanding of how the whole machine works. You notice patterns, and, crucially, you develop intuition.
Automation short-circuits that process. When we manually investigate and fix an issue, we naturally look at the logs, the upstream and downstream dependencies, the state of the system. That process builds intuition about how the system behaves under stress.
Automated remediation removes that observation window entirely. Junior engineers never see the failure mode, with the result being that the system recovers before anyone has learned anything. Our approach was to log every automated remediation and trigger a review if the same fix fired repeatedly. The automation didn’t disappear, but it couldn’t become a black box.
If you don’t use it, you lose it — and if automation means you never use it, the skill never forms at all. Consider this quote from Lisbeth Bainbridge’s seminal paper Ironies of Automation (an ephemeral but often-topical piece of research)-
“There is some concern that the present generation of automated systems, which are monitored by former manual operators, are riding on their skills, which later generations of operators cannot be expected to have.”
This is both a present and future challenge.
4. A green dashboard isn’t evidence of resilience
If your dashboards are always green, you might assume you’re resilient —-when in fact, it just means you have a green dashboard.
The real test? Ask your team to walk you through how your system fails.
To clarify, not the architecture diagram, or the runbook index: the specific, concrete ways the system breaks – and then what happens.
In my view, a strong indicator of resilience is how a team responds when something unexpected happens: not just the failures they’ve seen before, but the ones they haven’t. Knowing how your system typically fails is valuable, but that’s system knowledge. Resilience is what kicks in when that knowledge runs out.
The second indicator: runbooks built from real incidents, not theoretical procedures. Theoretical runbooks describe how things should work. Real ones describe how things actually go wrong, based on past experiences.
Never waste a good incident. Even (or sometimes especially) a small one.
5. Bonus – Chasing TTR is not optimising resilience.
Mean time to recovery, Mean time to resolution – these are the metrics often organisations grab at when they need to show that their systems are resilient.
These metrics aren’t measuring resilience. They’re measuring speed (and speed is often the last thing an incident responder can control.…).
The problem with optimising for TTR is the same problem as over-automating: the focus shifts to restoring the service quickly, and understanding the failure becomes secondary. You’re treating the symptom, not building the capability.
I’ve personally seen systems repeatedly restarted during incidents just because it reduced the downtime numbers – while the underlying cause went un-investigated. This is Goodhart’s Law playing out in real time: the moment a metric becomes a target, it starts incentivising the wrong behaviours. Teams optimise for the number, not the outcome. Until that trigger became a much bigger problem.
A fast restart is not a sign of a resilient team. It might be the opposite. Automation can bring a service back in seconds. That doesn’t mean anyone learned anything. And the next time that failure mode appears – more complex, higher stakes – the team is no better prepared than before.
Resilience is built through understanding failure, not recovering from it quickly. Those are two very different things.
Ultimately, resilience isn’t the absence of incidents. It’s the depth of understanding built by working through them. Jumping back to Ironies of Automation – ‘No one can be taught about unknown properties of the system, but they can be taught to practise solving problems within the known information.’
At Uptime Labs, we help engineering teams build those skills before a real incident demands them. You can try one of the incident training simulations I’ve developed here – would love to hear your thoughts.
References
This article owes a debt of gratitude to the This is Fine! podcast and particularly this episode, whose rich discussion helped guide our research and thinking.

Karan Nagarajagowda




