How Crisis Reveals the Truth About Complex Systems


Ready to make incident response your competitive advantage?
See how Uptime Labs builds provable, scalable incident response capability across your organisation.
Note: I write this as an engineer who has spent years watching systems fail in ways no one predicted. The closer you get to the sharp edge, the clearer it becomes that failure has the same signature across domains.
It is after one in the morning near Bishkek. A cargo Boeing 747 freighter from Hong Kong is on final approach to Manas Airport in freezing fog. The crew has had several days of rest, the aircraft is technically sound, and the air traffic controllers are trained and current. The runway is long and equipped for precision approaches. On paper, everything is under control.
Yet, the approach does not follow the planned profile. The jet crosses the threshold of runway 26 significantly higher than the procedure requires and continues to float. It finally touches down not near the aiming point, but roughly nine hundred meters beyond the far end of the runway, then overruns, breaks apart, and collides with houses in the nearby settlement. Thirty nine people on the ground and all four crew members lose their lives.
The investigation that follows is meticulous. Over more than one hundred pages, the final report reconstructs the flight, analyses crew training and duty time, reviews meteorological data minute by minute, examines every major system on the aircraft, and inspects the condition of navigational aids, runway lighting, and emergency response. It documents in detail how the aircraft was configured, where wreckage was found, and how the organisation trained and supervised the crew.
The report is not simply a record of tragedy. It is an audit of the entire socio technical system that allowed a high energy aircraft to arrive too high, land too long, and continue into houses beyond the aerodrome boundary. It is a textbook example of what a serious post incident review can be.
On 18th of November 2025, traffic across much of Cloudflare’s global network begins to fail. Users see error pages indicating problems inside Cloudflare, and five hundred class errors spike into the tens of millions of requests per second.
The cause is not an external attack. An internal change to permissions in a ClickHouse database that generates a configuration feature file for the Bot Management system accidentally doubles the number of features written. The file becomes larger than the proxy software expects. When the new file propagates to thousands of servers, the module that reads it exceeds its feature limit, panics, and causes the core proxy to fail. For customers on a new proxy engine, traffic turns into five hundred error codes; for others, bot scores silently degrade to zero, breaking rules in a more subtle way.
Engineers initially suspect a massive denial of service attack, in part because the company status page, hosted on external infrastructure, happens to be down for unrelated reasons. Only after they correlate the pattern of configuration changes and feature file sizes do they stop the bad file, push a known good one, and restart the fleet. Recovery is complicated by systems that depend on the same proxy and by a backlog of requests that surge back in when services are restored.
In 2017, an engineer working on the Amazon Simple Storage Service uses a standard operational playbook to remove a small number of servers in a billing subsystem. A parameter is entered incorrectly and a much larger set of servers is removed, including nodes that support the index and placement subsystems that store metadata and manage allocation for objects. These subsystems require full restart and integrity checks. During that time, S3 cannot serve read or write requests in the northern Virginia region. Many other services that depend on S3, such as new EC2 instance launches and some Elastic Block Store operations, also fail. Even the service health dashboard cannot be updated for a period because it depends on S3 in the same region.
It is important to acknowledge a stark difference in stakes, no one dies when a server fails. The tragedy of Flight 6491 is measured in human lives. The cost of a digital outage is measured in frustration and lost revenue. Yet, while the consequences differ by orders of magnitude, the mechanisms of failure are often identical. The cognitive traps, organizational blind spots, and hidden complexities that bring down a Boeing 747 are the same forces that crash a global network.
A freighter in freezing fog. A global content delivery network. A cloud object store at immense scale. Yet their post incident reviews converge on a set of practices and concepts that are valuable for any modern digital infrastructure organization.
What makes a good post incident review?
Across aviation and large scale internet services, effective post incident reviews share several characteristics.
First, they reconstruct reality in detail. The Manas report reconstructs the flight using recorder data, radar tracks, and air traffic control transcripts, then matches that against technical examination of wreckage, crew records, maintenance history, and weather instrumentation. The Cloudflare and Amazon documents explain which subsystems were involved, what specific configuration changes occurred, and how those changes propagated through networks and services.
Second, they treat incidents as system problems rather than individual blame. The Manas report evaluates training programs, procedures, meteorological support, and airfield equipment as well as crew decisions. The AWS S3 account explicitly notes that the engineer followed an established playbook and shifts the focus to the tooling that allowed too much capacity to be removed and the lack of safeguards against taking subsystems below minimum capacity. Cloudflare’s writeups emphasise configuration architecture, rollout mechanisms, feature limits, and observability, not personal fault.
Third, they orient strongly toward future change. The Manas report lists specific safety recommendations on training revisions, procedures, and equipment checks. AWS commits to slower and safer capacity removal, to minimum capacity safeguards, and to further partitioning of key subsystems into smaller cells to limit blast radius and speed recovery. Cloudflare accelerates adoption of progressive rollouts, adds global feature kill switches, increases capacity for critical services, and tags retries from dashboards to improve visibility.
In short, a good post incident review is a technical narrative with three properties:
- It is specific in the way it reconstructs what actually happened.
- It is systemic in the way it considers organisational, environmental, and technological contributors.
- It is forward looking in the way it priorities architectural and procedural change over individual blame.
These three properties matter because incidents do not occur in isolation. They are moments when the limits of a system become visible. A post incident review therefore does more than explain a discrete failure. It reveals how a system behaves when pushed toward the edge of its performance envelope. This is where the study of resilience becomes essential.
The idea of resilience, especially as articulated by David Woods, provides a deeper frame for understanding why certain systems fail abruptly while others absorb, adapt, and continue. Woods describes four complementary concepts of resilience that together explain what gives a system adaptive capacity before, during, and after disruption.
Understanding these concepts allows post incident reviews to move beyond correcting individual faults and toward identifying how systems can anticipate pressures, recognise emerging bottlenecks, stretch when confronted by surprise, and continue to evolve. In this way, Woods’s work connects directly with the purpose of rigorous post incident analysis: to illuminate where adaptive capacity was present, where it was missing, and where it must be built.
David Woods and the four concepts of resilience
Safety researcher David Woods proposes four distinct concepts of resilience that together frame how systems handle disruption.
- Resilience as rebound, asks why some systems recover from trauma and return to operation.
- Resilience as robustness, focuses on extending a system’s performance envelope for known disturbances.
- Resilience as graceful extensibility, looks at how systems stretch when events push them beyond their known boundaries and avoid brittle collapse.
- Resilience as sustained adaptability, examines architectures and governance that preserve the ability to adapt over many cycles of change.
The difference between Robustness and Graceful Extensibility, It is easy to confuse these two, but the distinction is vital. Think of Robustness as a shock absorber on a car. It is designed to handle bumps up to a certain size. If you hit a pothole within that range, the system absorbs it, and the ride remains smooth. Graceful Extensibility is what happens when you hit a pothole bigger than the shock absorber can handle. Does the axle snap and the car flip (brittle failure)? or does the driver instinctively swerve while the suspension bottoms out with a loud bang, but the car stays on the road? Robustness is about absorbing the known; Extensibility is about stretching to handle the unknown.
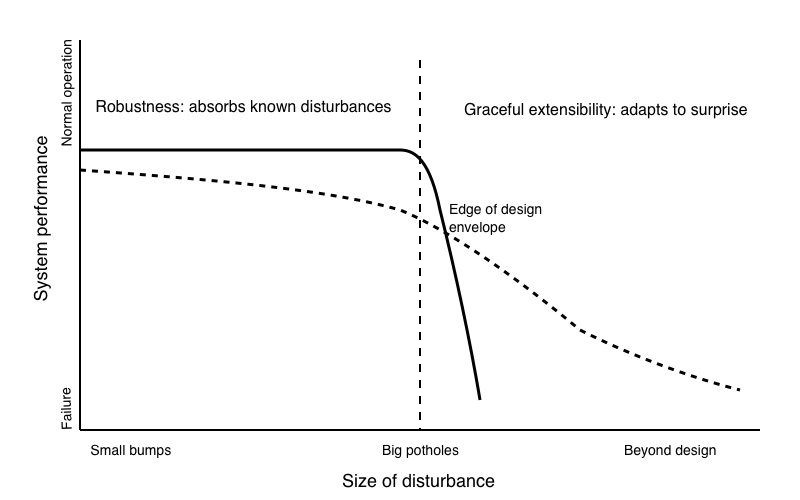
These aviation and cloud incidents illustrate why it is not enough to think only in terms of rebound or robustness.
The Manas accident shows that a system can operate for many years without serious events yet still be brittle at the boundaries. The runway was long (robustness), the aircraft well maintained, and the crew certified. But the combination of fog, vertical visibility, approach profile, workload, and perhaps organisational expectations about continuing approaches in marginal conditions created a situation where small deviations led to catastrophic overrun. Counting safe landings did not reveal that brittleness.
The AWS and Cloudflare incidents show robust systems in normal operation. S3 routinely handles enormous loads and survives component failure. Cloudflare routes and inspects traffic at global scale even under attack. Yet both systems failed when events happened outside their well modeled disturbance sets. A configuration feature file became larger than any previously seen. A capacity removal tool operated in a regime where its implicit assumptions about scale and topology no longer held.
Thinking in terms of graceful extensibility, the question becomes: what extra adaptive capacity existed before these events to detect and handle surprise, and how was that capacity eroded or not developed.
In the Manas case, the available capacity included go around options, adherence to approach minima, better recognition of unstable approach criteria, and more conservative decision making in very low vertical visibility. The investigation suggests that organizational and procedural context did not sufficiently support those capacities under pressure.
In the cloud cases, extra capacity could have been provided by stronger feature validation on configuration size, global and rapid kill switches for problematic modules, more complete separation between internal configuration data and critical data plane software, and rollout systems that quickly detect bad deployments and roll them back automatically. Both Cloudflare and AWS explicitly commit to such changes in their follow up actions, which are attempts to increase graceful extensibility and sustained adaptability rather than only robustness.
Woods also warns that simply expanding robustness in one dimension can increase brittleness elsewhere. The Cloudflare bot feature file illustrates this. Giving the machine learning system more detailed features seemed beneficial, but the underlying limit on feature count was not updated. Robustness in threat detection collided with hidden fragility in configuration ingestion.
For digital infrastructure leaders, the practical implication is that post incident reviews must explicitly ask where the system was near its adaptive limits, how it stretched, and what trade offs were made in design and operation that may have shifted brittleness somewhere else.
These four concepts show that resilience is not a single trait but a collection of adaptive capacities that systems must cultivate long before disruption occurs. They also highlight a common theme across all incidents examined: systems fail not because individuals act with ill intent, but because the surrounding structures, constraints, assumptions, and trade offs shape how people and technologies behave under pressure. When a system approaches the edges of its performance envelope, people are often the last line of adaptation, absorbing complexity that the design did not anticipate.
This brings us to the role of blameless culture and real accountability.
Blameless culture and real accountability
Blameless culture does not mean absence of accountability. It means refusing to stop at blaming individuals when the real leverage lies in system design, management decisions, and organisational context.
The Manas report describes crew qualifications, training records, and previous operations in detail, then examines procedural design, meteorological support, aerodrome equipment, and air traffic control practices. It treats the accident as the result of many interacting factors rather than a single error.
AWS describes the engineer who executed the capacity removal command as using an established playbook and being authorised to do so. The focus of corrective action is the tool that allowed a single command to remove so much capacity, the absence of minimum capacity safeguards, and the lack of partitioning in critical subsystems.
Cloudflare’s public articles provide detailed descriptions of component behaviour and architecture, admit where assumptions were wrong, and describe planned improvements to rollouts, feature flags, and telemetry.
In all three, blame is directed at insufficient guardrails, incomplete models of risk, and gaps in observability. Individuals are still responsible for learning and improvement, but they are not scapegoated. This approach is essential if you want engineers to report near misses honestly, challenge assumptions, and push for architectural changes that may be politically inconvenient.
Ineffective measures of resilience
These cases also reveal what resilience is not.
Resilience is not the absence of incidents. The 747 had flown safely many times. S3 had operated for years without a full restart of the index subsystem. Cloudflare had processed massive numbers of requests with very few total outages. None of that prevented failure once conditions moved outside their modeled envelopes.
Resilience is not simply robustness. Extra runway length, large fleets of servers, and sophisticated distributed databases all add robustness to common disturbances. They do not guarantee the ability to adapt gracefully to new kinds of events, such as a bad configuration file that exceeds a limit or a confluence of meteorology and human decisions that leaves no stopping distance. Woods argues that treating resilience as robustness confuses improvements inside the known envelope with the ability to handle model surprise.
Resilience is also not mean time between incidents or average availability expressed as a number with many nines. Those figures matter, but they do not capture what sources of adaptive capacity exist before an event or how the system behaves near its boundaries.
For digital infrastructure organisations, this means that resilience metrics should pay attention to things like the speed and safety of configuration rollouts, the availability and use of feature kill switches, the diversity of recovery strategies, the rate at which near misses are reported and acted on, and evidence that the system can be modified safely in production without extensive heroics.
What digital infrastructure can learn from aviation?
Aviation safety has been built on disciplined analysis of accidents and serious incidents. Several concepts from aviation are particularly useful for cloud and software organisations.
Threat and error management treats human error as expected and focuses on how threats are anticipated, how errors are detected and corrected, and how barriers fail. Applied to S3 and Cloudflare, this means expecting configuration mistakes, tool misuse, and unexpected interactions between services, then designing multiple layers of detection and mitigation rather than relying on perfect operation.
Crew resource management emphasises communication, shared mental models, and assertive cross checking in the cockpit. For incident response teams, this translates into clear declaration of roles, explicit call outs of observations and uncertainties, and encouragement for junior engineers to question assumptions in real time.
Formal occurrence reporting systems in aviation collect data on minor events, unstable approaches, and procedural deviations. They build a picture of where the system is stretching before disasters occur. For digital organisations, similar value comes from recording small deployment problems, partial rollbacks, and near misses, then reviewing them with the same seriousness as major incidents.
Finally, the structure of aviation investigation itself is a model. It is independent, draws on multiple disciplines, and looks beyond the last link in the chain. It asks how training, regulation, economic pressure, equipment design, and organisational culture together set the stage for the specific decisions made on the day.
If digital organisations adopt even part of this mindset, their post incident reviews will become more than compliance documents. They will become systematic explorations of how complex adaptive systems succeed and fail, and how to engineer graceful extensibility and sustained adaptability rather than only robustness.
In summary The Manas freighter accident, the Cloudflare outages, and the Amazon S3 disruption are very different events in very different sectors. They involve runways and runbooks, glideslopes and feature files, aircraft systems and distributed databases. Yet the value of a good post incident review is the same.
It reveals how reality actually unfolded rather than how we wished it had. It treats incidents as system phenomena, not personal failures. It connects immediate remediation to deeper questions about adaptive capacity and architecture. It respects the people involved by learning from their actions rather than punishing them. It strengthens trust with customers and the public through transparency and concrete commitments.
Most importantly, it moves our understanding of resilience away from simple rebound and robustness toward graceful extensibility and sustained adaptability, in the sense David Woods describes.
For leaders of modern digital infrastructure, the message is clear. Incidents are not just failures to be hidden or survived. They are, in Lagadec’s phrase, “abrupt audits” of everything that was left unprepared. A disciplined, honest, and systemic post incident review turns that audit into a source of design insight, operational learning, and long term resilience.
Gamunu Balagalla




