
Ready to make incident response your competitive advantage?
See how Uptime Labs builds provable, scalable incident response capability across your organisation.
Introduction
A few weeks ago, I wrote a blog post, which advocated having the technical foundations of resilience.
That was Principle 2 of my Incident Principles for CTOs series. This is Principle 3.
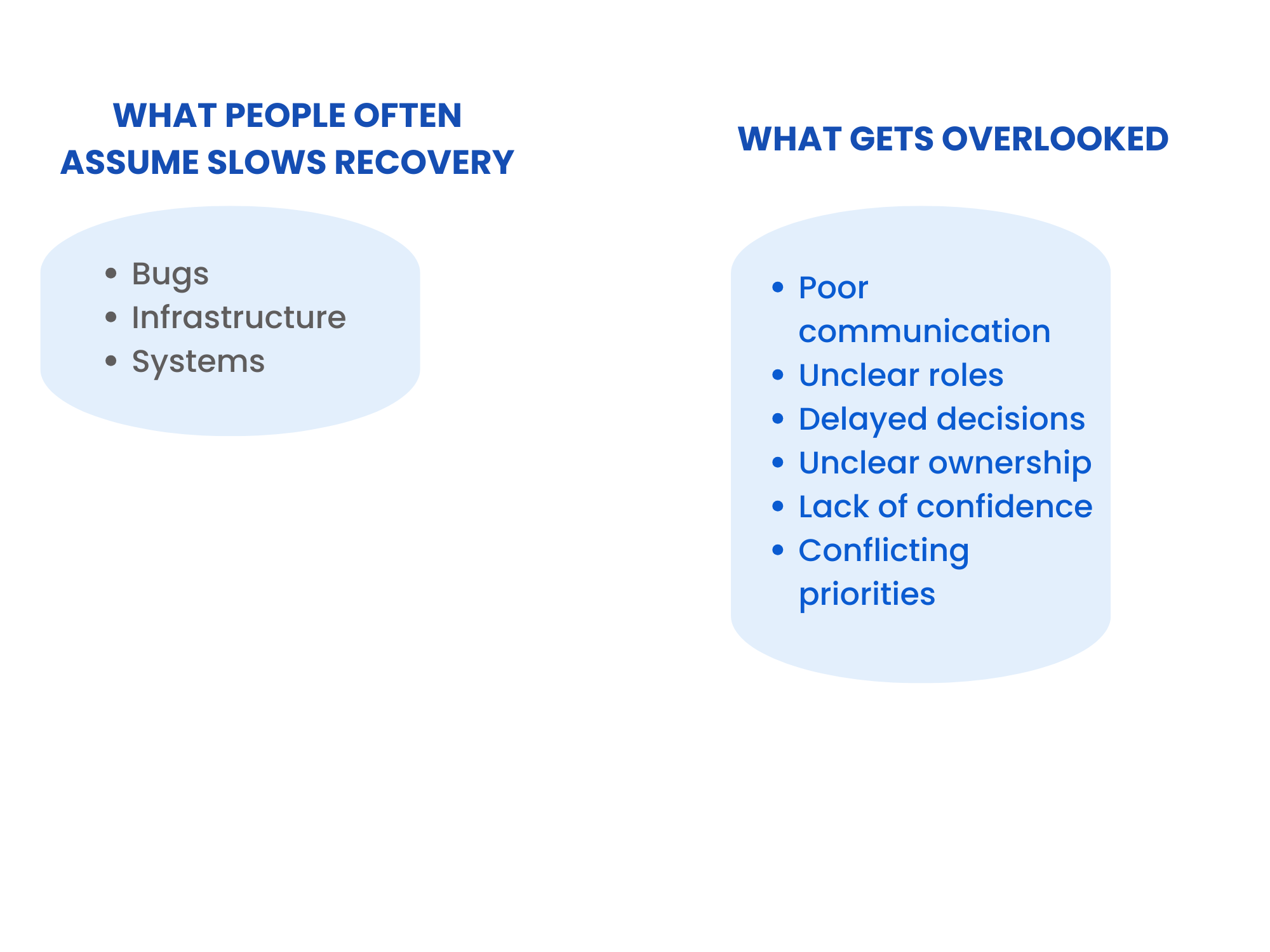
When incidents happen, most organisations instinctively look at the technology.
Was it a scaling issue? A bad deploy? A missing alert?
Those questions matter. But orgs then forget to ignore that the human layer is what brings incidents back under control.
This post champions the often-overlooked skills that turn a technical failure into a contained one: the human capabilities that step in when the systems can’t.
Moving away from surface-level incident measurement
Every CTO (should) know that incidents are inevitable. You can invest in architecture, observability and resilience patterns (and you should). And, in complex systems, you don’t get perfect foresight.
What actually matters isn’t whether, or how often incidents happen:
It’s how your people respond when they do.
Failures aren’t just technical
In practice, most failures during incidents aren’t purely technical, they’re also human, such as:
- unclear ownership
- slow decision-making
- poor communication
- lack of confidence
- hesitation under pressure
… are just a few examples of where humans can exacerbate existing failures. The result? Recovery slows, confusion spreads and impact grows.
And they don’t show up in your architecture diagrams.
… Therefore, the fix can’t be purely technical
Strong organisations recognise this early.
They understand that technical resilience must be matched by human readiness.
That means investing in:
1. Psychological safety
If people are afraid of the consequences of making mistakes, they delay decisions.
High-performing teams create environments where it’s safe to act, safe to escalate and safe to be wrong – because speed often matters more than perfection in an outage.
Recall Stuart’s post last year, Your Brain on Incidents, where he discusses a practical example of psychological safety…
‘On Sunday evening, paranoia crept in as I became convinced that I was going to be fired on Monday morning….
As I arrived in the office on Monday, I was met by my boss…His response astonished me. He thanked me profusely for my efforts, told me I should be proud of my performance, shook my hand, and told me to take a day or two off to rest.
That response contributed a long way to my feeling comfortable about being on call in the future.’
And of course, part of this psychological safety is fostering a blameless culture (I have, of course, linked to John Allspaw’s seminal 2012 piece on this).
2. Blameless culture
After an incident, the question isn’t “who caused this?”
It’s “what did we learn?”
Blame shuts down learning. Curiosity accelerates it.
The most mature teams treat every incident as a feedback loop – not just into systems, but into behaviours.
As well as being fair, John’s article points towards a number of practical ways you can foster this culture:
- People own mistakes by educating the rest of the org about how not to make them.
- Gather multiple perspectives on the same incident.
..and
3. Consistent leadership
Incidents are leadership moments.
They reveal how decisions are made, how teams coordinate, and how clearly information flows.
This isn’t something you can improvise in the moment, without first building expertise.
It’s something you prepare for.
4. Continuous learning
Elite organisations don’t just measure downtime.
They watch whether fixes are systemic or cosmetic. They watch whether lessons travel across teams or die in the team that had the incident. Every incident should leave the system stronger, not just technically, but operationally:
- clearer roles
- better communication patterns
- faster escalation
- stronger decision-making
If the same incident happens twice in the same way, the problem isn’t just the system. It’s the organisation.
One responder isn’t enough
The reality is simple:
You can’t rely on a few experienced individuals to save the day.
That’s not resilience. That’s luck, or worse, having one, increasingly-burned out hero responder.
Real resilience comes from having many capable responders, operating with shared expectations, clear communication and confidence.
Where does the CTO fit in?
Ultimately, the CTO is responsible for turning incident learnings into real change. It’s not enough to run a post-incident review and capture actions. The critical question is whether those actions (actually) get prioritised and delivered.
After every incident, I always ask: what came out of this, and are those improvements happening?
That might mean investing in the team – adding headcount to remove single points of failure or providing better training and support. It might mean prioritising specific fixes or process changes identified during the review. But whatever the outcome, it’s the CTO’s role to drive it forward.
If those actions are ignored, you’re not just missing technical improvements – you’re ignoring the people side of incident response. Often, incidents expose gaps in skills, confidence or experience. It’s not fair to expect people to handle high-severity incidents if they haven’t been prepared for them.
That’s why there’s a clear link to training and development. Do your teams actually have the skills to respond effectively? Have they practised? Are they ready?
As a leader, your role doesn’t end when the incident is resolved. When the dust settles, you need to go back to your teams and ask: how did that feel? what do you need to do better next time?
And then – most importantly – you champion those improvements. You prioritise them. You make sure they happen. That’s how resilience is built.
Conclusion
And in the moments when systems are failing and pressure is high – it’s the people side that determines whether an incident stays controlled or turns more costly; more prolonged; more damaging.
The best CTOs understand this: They don’t just try to build resilient technology.
They build resilient teams.

Joe Mckevitt


.png)

