5 Foundational Incident Response Skills, Demonstrated Live

.png)
Ready to make incident response your competitive advantage?
See how Uptime Labs builds provable, scalable incident response capability across your organisation.
The setup was simple:
Charlene, an Uptime Labs engineer, sat down in front of a room full of engineers and hit Start on a SEV1 simulation. The incident was based closely in a real one. The audience sat with bated breath.
Over the next 20 minutes, Charlene navigated a global e-commerce payment outage, a resistant engineer, a demanding CEO and one very busy Slack channel. This turned out to be a better education in incident response than many engineers get in years of oncall rotations.
Quick note - SEV1 is our preferred incident severity scale, which references the most critical incident relatively. It might be referred to in other areas as a a P1.
In other words, a SEV1 is a big deal. It's a mission-critical issue. It’s the type of thing that people wake you up in the middle of the night for. (If you’re curious about incident severity, you can also read our take on whether there’s actually a point to assigning severity).
The scenario
The scenario: Online Boutique, a fictional global e-commerce company, is seeing 100% of UK checkout transactions fail.

Just a few of the consequences of this failure include:
- Revenue haemorrhaging by the minute
- The CTO urgently wanting updates
- The CEO demanding revenue impact numbers
What could be the culprit cause? That would be telling :)) What I can tell you is the 5 skills that the incident simulation highlighted:
Skill 1: Reproduce the issue yourself
Before Charlene did anything else, she went to the website and tried to complete an order. It failed immediately.
The reason why you should reproduce the issue is just to get an idea of the underlying impact as a starting point. There are also clues usually when you reproduce the issue, which gives you better context and clues for triage steps as well.
Plenty of responders jump straight to pinging engineers or scanning dashboards. Reproducing the issue yourself gives you the error state, the stack trace and a concrete handle on what broken actually means i.e. not what someone else says it means. It's one of those habits that saves minutes, and during a critical incident, it's one of those habits that saves minutes during a critical incident.

Skill 2: Understand the importance of effective impact assessment
Charlene spent several exchanges probing Bob, the customer success lead, before she raised a ticket. How many users were affected? Which regions? What were they seeing exactly?
Only once she had enough data did she declare a SEV1. From running hundreds of these simulations, I can confirm many responders declare severity too early or on too little information. Then they spend the rest of the incident managing the wrong expectations upward.

Skill 3: Use the data
One finding Uptime Labs keeps seeing across simulations: 20% of participants never open the metrics dashboard.
In this scenario, the telemetry was the smoking gun. A deployment annotation lined up almost exactly with the drop in orders. Without the metrics, Charlene would have had a hunch. With them, she had a working theory. Ergo, this theory carved a much shorter path to the fix.
Note that, however, telemetry won't always lead you to take the right action. So in this case, the telemetry was the smoking gun, but the fact that it was the smoking gun was only determined in retrospect after the decision to act on it had been made. What it did do was to facilitate a hypothesis being generated, which in turn facilitated a way of testing the hypothesis, which in this case proved to be true.
The vantage point:
This is the point in the incident where you might take a second to think: what have I done so far in the first couple of minutes to help me better manage the incident?
At this point reproduced the issue, you've got credible information about your understanding of the customer impact, and you have metrics that give you a signal on various hypotheses to work with and apply in the first three skills, which is critical to impact assessment.
Now you can move to a much more effective and targeted triage step.
%20-%20foundational%20incident%20response%20skills.png)

Skill 4: Restoration-first mindset
Once Charlene identified the likely culprit, she pushed for a rollback. Daniel pushed back; he wanted to investigate further before touching anything. Yet Charlene held the line.
The pushback from Daniel, incidentally, was deliberate. It was lifted directly from a real incident, where an engineer was convinced the evidence wasn't conclusive enough to justify a rollback (even while the revenue counter was soaring).
As the Incident Commander, you have to make decisions under uncertainty - rolling back without certainty it will fix the issue. That's the point. The alternative is a longer outage while the engineer investigates root cause, resulting in more revenue lost.
(Side note: It was in retrospect the right call in this scenario, but note at the time rolling back carried a risk. It’s worth acknowledging that any decision you make under these circumstances of ambiguity and uncertainty have risks.
It's always possible that a decision with the intent of restoration could make things worse, and while restoration is obviously important, the approach should not be ‘restore at all costs’. because some costs are greater. For example, in one our drills, deleting a file restores service but gets the business in trouble with the regulator).

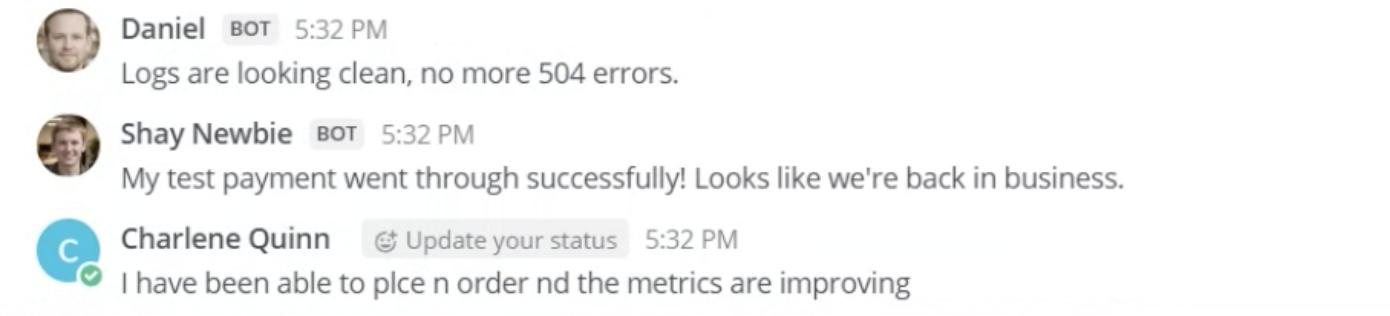
Skill 5: Validate before you close
When the metrics started recovering, Charlene didn't call it a day. She:
- went back to the website and completed a test transaction herself
- checked the logs with Shay
- confirmed with Bob that customers were able to check out again.
It's an easy mistake to make to declare victory too early. The validation steps mirror the impact assessment ones almost exactly: the same sources, the same questions, but looking for green signals instead of red ones.
Conclusion
Ultimately, if you're new to on-call and the idea of your first critical incident keeps you up at night, that's normal. Been there, done that. And the antidote isn't reassurance, it's challenging (yet fun) practice.
You can replay this exact simulation yourself, or join one of our upcoming events.
And for the seasoned responders reading this: may your rollbacks be clean and your Daniels cooperative.
You can also watch the full workshop here:
Joe Mckevitt

.png)
.png)

