Why Teamwork Makes (Or Breaks) Your Incident Response

.png)
Ready to make incident response your competitive advantage?
See how Uptime Labs builds provable, scalable incident response capability across your organisation.
High-severity incidents expose how a team really works together, usually within the first ten minutes. The technology gets the headlines, but resolving one almost always comes down to people: who is leading, who is listening and who is learning.
I’ve spent years leading incident response teams and designing drills for them, and the same teamwork patterns keep coming up. Here is what I’ve learned about what separates an effective recovery from a chaotic one.
The breakdowns that show up again and again
A few breakdowns appear in nearly every major incident:
- Role confusion in the first 10-15 minutes. Engineers tend to dive straight into troubleshooting before anyone has declared themselves the incident commander, communications lead or scribe. Nobody comes in and says, ‘Yes, I’m the engineering commander for today.’ That ambiguity sets the tone for everything that follows.
- Information and communication overload. Multiple teams start posting every warning and error they can see rather than triaging what actually matters, and the channel becomes noise.
- Hero-culture bottlenecks. Resolution stalls until the senior engineer who has seen it before is pulled in. That dependency feels reassuring in the moment but causes problems over time.
- A lack of shared situational awareness. Network, platform and application teams each work from different assumptions about what is happening. Consequently, they lose valuable minutes converging on a shared picture. This is the gap that grounding is designed to close.
- Emotional escalation. As the clock ticks, stress changes behaviour. People become defensive, blame shifts between teams (’I think this is a network issue’), and listening drops off. At a certain point people go into defensive mode: e.g. ‘it’s not my issue’.
The best incident response I’ve seen feels calm, structured and psychologically safe. That usually starts with senior engineers delegating ownership rather than becoming the single point of contact.
What good teamwork actually looks like
Here is a story that captures what changes when a team gets this right. A major intermittent issue had started causing 500 errors on login, sometimes for the same user and sometimes for different ones, with no obvious pattern. Intermittent failures are some of the hardest to resolve, because you cannot reliably reproduce them.
It was structure, not a single hero, that saved the day. We assigned ownership straight away: incident commander, application lead, infrastructure lead, communications and scribe. With roles clear, four or five teams could investigate in parallel rather than in sequence. The application team reviewed recent changes, infrastructure validated clusters and nodes, my SRE team analysed traces, and support worked out the customer impact by region.
The breakthrough came from a junior engineer. He noticed that the authentication failures were only happening on two specific servers behind the load balancer. From there, the platform team identified that those servers had been deployed recently with an incomplete configuration. We swapped them out and the incident was closed.
The lesson I took from it is that a clear command structure did not slow us down. It freed us to work in parallel, and it gave the most junior person in the room the space to make the most important observation.
Balancing speed and coordination
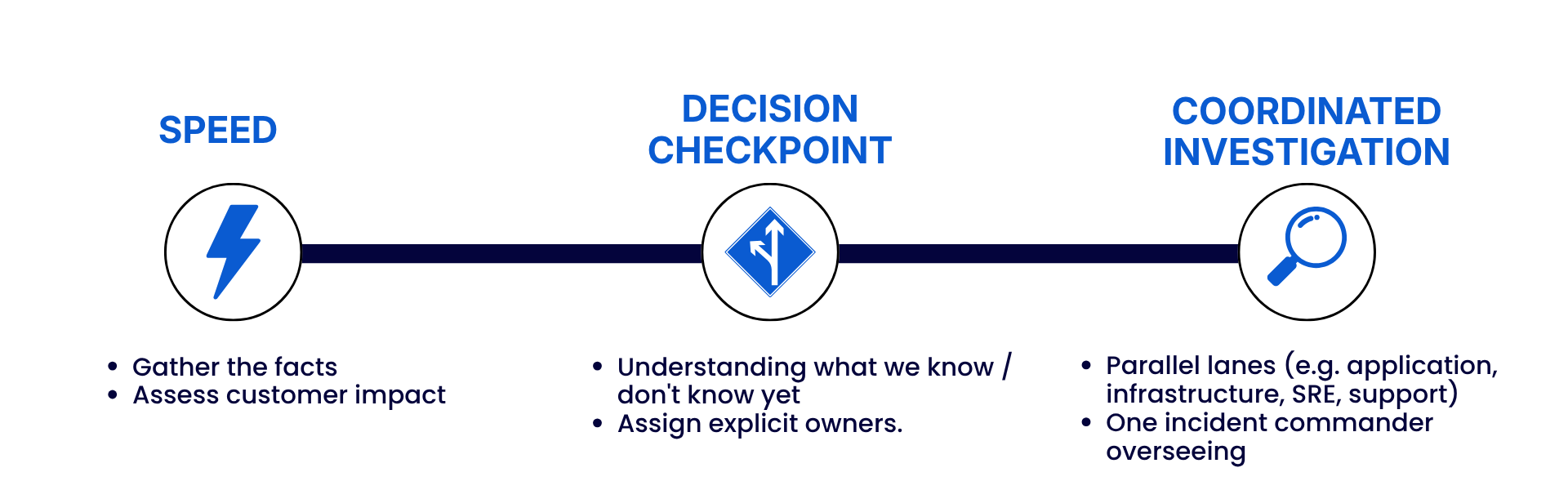
One of the hardest tensions in incident response is between moving fast and coordinating well. The way I handle it is to split the incident into phases.
For the first 5-10 minutes, speed matters most: stabilise the system, reduce customer impact and gather the facts. Then comes a decision checkpoint, where we;
- pause to summarise what we know
- what we still don’t know
- assign explicit owners to each open thread.
After that, the coordinated investigation begins, with teams working in parallel on their assigned areas while the incident commander checks that everyone is making progress.
Coordinate too early and you cannot assign the right things. Alternatively, keep moving fast without ever stopping to coordinate and you create chaos. The checkpoint is what holds the two together.
How to build these habits in drills
When I design incident drills, I deliberately build in conditions that force teamwork. I give players ambiguous symptoms, so they have to confirm what they are seeing with teammates and stakeholders instead of assuming. I give them incomplete information, handing over perhaps 20% of what they need so the rest has to be gathered across teams. I add communication pressure, with a simulated executive (Bez Jeffos) asking for updates and working theories, which forces clearer comms. And I put several responders in at once, which shows who:
- coordinates
- adds to the noise
- listens
- can delegate.
I don’t evaluate purely on time to recovery. I also look at whether decisions were documented, whether ownership was clear, whether anyone became a bottleneck and whether panic drove people’s behaviour.
What it comes down to
Good incident response takes more than technical skill. It takes technical skill that is well coordinated: clear roles, parallel work, an honest checkpoint and a culture where the most junior engineer feels safe enough to speak up. Get those right and the technical fix usually follows.
Karan Nagarajagowda




