Best Incident Management Platforms for SRE Teams (2026)
Ready to make incident response your competitive advantage?
See how Uptime Labs builds provable, scalable incident response capability across your financial services organisation.
The right incident management platform depends on your team size, toolchain, and whether you need a full alerting stack or a coordination layer on top of existing tools. This guide also covers a gap in the evaluation that most comparison guides overlook entirely.
Every incident management platform on this list solves the same core problem: when something breaks at 2 AM, your team needs to find the right people, coordinate a response, and resolve it fast. What separates the tools is how they do that, and for whom. This guide covers 8 platforms across the criteria that actually matter to SRE teams: integration depth, on-call management, AI capabilities, post-incident learning, and pricing transparency. For a broader look at the SRE toolchain beyond incident management, see 8 Best SRE Tools for Uptime and Reliability in 2026.
Every tool in this comparison manages the workflow of an incident: alerting, escalation, coordination, postmortems. What none of them can do is prepare your team to execute that workflow under pressure. Uptime Labs provides the readiness layer: realistic, hands-on incident simulations that build the muscle memory, communication skills, and decision-making these platforms assume your team already has.
The best incident management stack in 2026 pairs a strong platform with a training programme that ensures your team can actually use it when the next Sev-1 hits.
The 8 Best Incident Management Platforms for SRE Teams
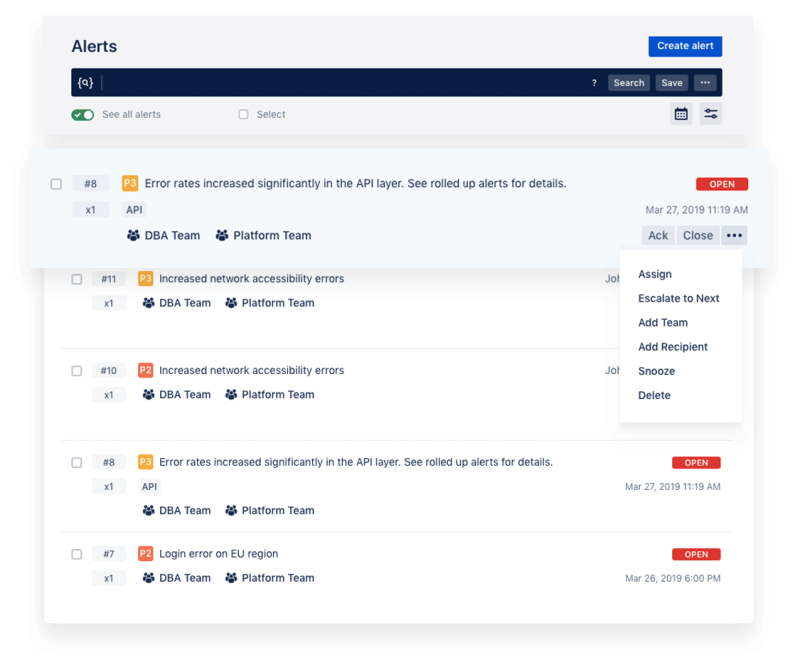
1. PagerDuty
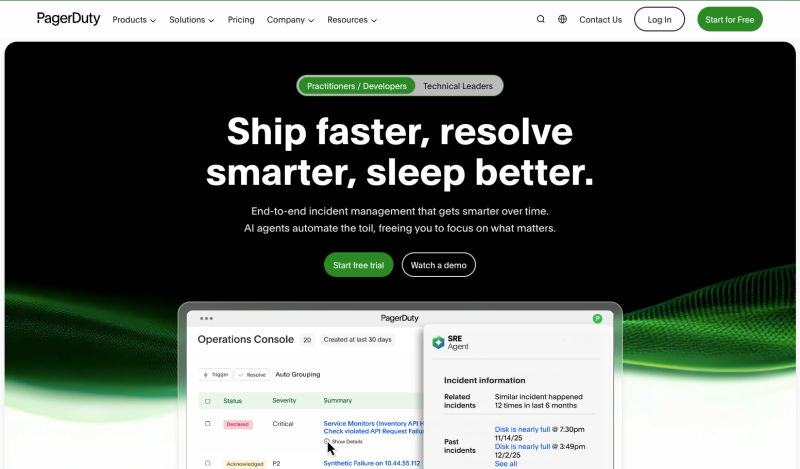
Since its inception in 2009, PagerDuty has dominated the incident management space, and the platform has become synonymous with on-call, with many SRE and DevOps teams referring to getting alerted as getting “paged.”
What it’s often known for:
With 750+ native integrations, extensible APIs, and customisable workflows, PagerDuty can fit into and augment almost any team’s toolkit. On-call scheduling is mature and flexible, with schedule layering, rotation management, calendar sync via iCal, and override controls that most teams can configure without friction.
PagerDuty has also introduced AI-driven features, including agentic AI functionality within the Operations Cloud, designed to handle repetitive tasks and speed up incident response.
Could be a good fit for: Large enterprises with deep ITIL investment, complex multi-team escalation requirements, and budget to match.
2. incident.io
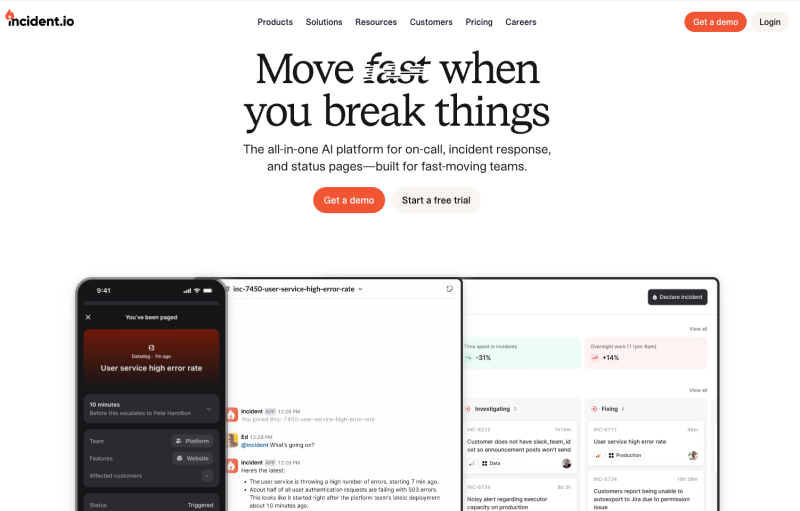
incident.io is a strong option for SRE teams whose incident coordination already lives in Slack. It was built for chat-first workflows from the ground up, rather than bolting Slack integration onto an existing alerting platform.
What it’s often known for:
When incidents occur, incident.io automatically creates dedicated Slack channels, pages appropriate responders, and executes workflows without forcing teams to switch between tools during critical moments. AI-powered investigation accelerates root cause analysis and reduces manual triage work, and the platform extends natively into Microsoft Teams for organisations that run on both.
The automation handles coordination mechanics, but the quality of the response still depends on whether the humans in the channel know how to scope the incident, communicate clearly, and escalate at the right moment. That’s a skill gap no ChatOps automation can close.
3. Rootly
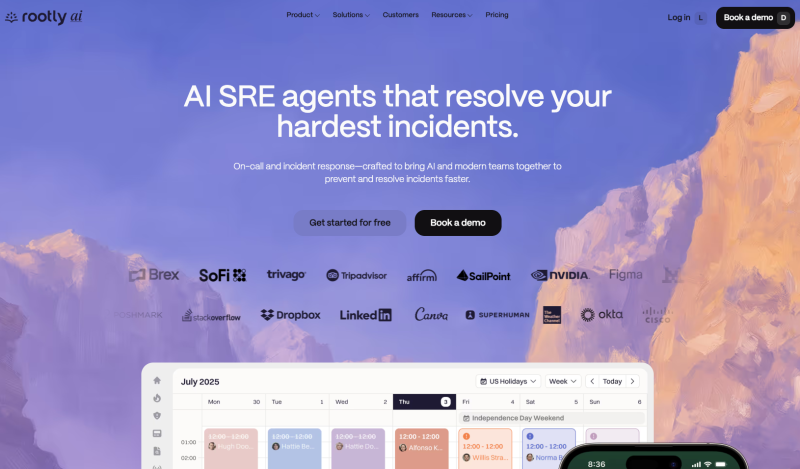
Rootly goes deep into automation. If your team wants every step of the incident lifecycle, from channel creation to postmortem generation, to happen without manual intervention, Rootly is a strong contender.
What it’s often known for:
When an incident begins, Rootly can automatically create a dedicated Slack channel and invite the correct on-call engineers, start a video conference call, create a corresponding ticket in Jira or Shortcut, and update a stakeholder-facing status page, reducing the operational burden on engineers during a high-pressure event.
Rootly provides flexibility with a dual approach to on-call management: it offers its own native on-call scheduling and alerting that can fully replace existing tools, while also maintaining a bi-directional integration with PagerDuty, allowing teams to either consolidate their stack or run both in parallel during a migration.
4. FireHydrant
FireHydrant is a process-oriented platform. If your team already has documented response playbooks and wants to codify them as automated runbooks rather than relying on tribal knowledge, FireHydrant is built for that workflow.
What it’s often known for:
FireHydrant orchestrates the complete incident lifecycle through automated stages: detect, respond, resolve, review, and learn. The platform eliminates manual handoffs between stages, with workflow automation covering stakeholder notification, status page updates, and postmortem scheduling.
A standout feature is its service catalog, which maps services, dependencies, and ownership to form the foundation for context-aware incident response. In practice, that means the platform can surface the right runbook and page the right service owner based on which service is affected, rather than relying on a human to work that out during a live incident.
FireHydrant uses flat-plan pricing rather than per-seat licensing. The Platform Pro plan costs $9,600/year and includes up to 20 responders, runbooks, integrations, status pages, service catalog, SSO, on-call scheduling, and alerting via Signals. For teams that have dealt with per-seat costs scaling unpredictably across the other platforms on this list, that model is worth serious consideration.
Could be a good fit for: Engineering teams with mature, documented response processes who want to automate those processes as runbooks, particularly teams under 20 responders who benefit from flat-plan pricing.
5. Opsgenie: Context Only, Not a Recommendation (Sunsetting April 2027)
If you are currently on Opsgenie, you need a migration plan. Atlassian has announced that Opsgenie will no longer be available for new purchases or trials starting June 4, 2025, with end of support on April 5, 2027. All Opsgenie data will be deleted after that date.
Opsgenie was acquired by Atlassian in 2018 and had been a reliable, well-regarded alerting platform. For many mid-market IT operations teams, it was the sweet spot between PagerDuty’s enterprise pricing and basic monitoring tool notifications. Now that sweet spot is gone.
Atlassian’s official recommendation is to migrate from Opsgenie to Jira Service Management combined with Compass, their developer portal. For teams that used Opsgenie as part of a modern DevOps workflow, that path has been poorly received: JSM is rooted in a traditional ITSM model that many SRE teams deliberately moved away from, and Compass as a replacement for Opsgenie’s alerting capabilities is a significant step down in maturity.
The Opsgenie sunset is a forcing function to re-evaluate your entire incident management approach. The platforms most frequently discussed as migration destinations in engineering communities are incident.io, Rootly, Squadcast,PagerDuty and FireHydrant.
If you are migrating, treat it as an opportunity to assess your incident response process alongside your tooling. A platform migration that carries over the same unclear escalation paths and undocumented response patterns just recreates the problem in a new interface. For a framework on getting escalation right before you migrate, see incident escalation process, and for a deeper look at the judgement calls involved, see too soon or too late: the incident escalation dilemma.
6. Squadcast
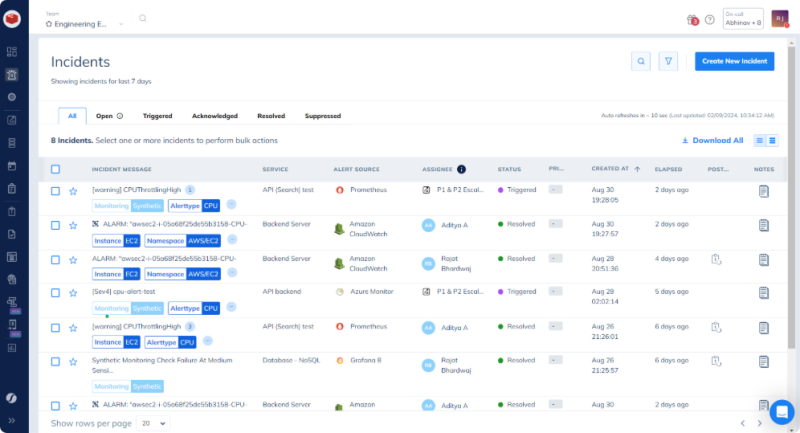
Squadcast is the only platform on this list with SLO monitoring and error budget management built directly into the incident management workflow. For teams running formal SRE programmes, that means incident response decisions can be informed by remaining error budget in real time..
What it’s often known for:
Squadcast gives SRE teams SLO monitoring and error budget management alongside their incident response workflow, which is a meaningful differentiator for teams running formal SRE programmes with defined service level objectives. No other platform on this list integrates reliability metrics this directly into the incident management layer. Note that SLO tracking is available from the Premium tier ($29/user/month or $24 annual), not the entry-level Pro plan.
At the Enterprise tier, the platform adds AI-driven alert clustering that groups related incidents automatically, reducing noise and preventing duplicate response efforts, alongside AI-generated incident summaries and intelligent alert grouping. On-call rotation management with automatic handoffs and escalation policies is available across all tiers.
Could be a good fit for: Mid-market SRE teams running formal SLO programmes who want incident management and reliability metrics in a single platform, and who are comfortable at the Premium or Enterprise tier where those capabilities live.
7. Xurrent

For teams that need to satisfy both SRE workflows and traditional IT operations requirements within a single platform, including change management, request management, and ITIL-aligned processes, Xurrent bridges that gap without forcing a choice between the two.
What it’s often known for:
Xurrent (formerly 4me) combines incident management, request management, and change management in a single multi-tenant SaaS platform. For organisations that need to serve both SRE teams and broader IT operations, that unification avoids the common problem of running separate tools for incident response and service delivery. AI is embedded by default through Sera AI, which handles ticket classification, routing, summaries, and knowledge generation across all tiers rather than gating it behind an enterprise paywall. The platform also includes a native virtual agent that handles requests through Slack, Teams, and a web portal, escalating with full context when human intervention is needed.
Xurrent is built for enterprise compliance requirements from the outset, with SOC 2, ISO controls, RBAC, audit trails, and BYOK encryption options. For regulated industries where those certifications are table stakes, that baseline matters.
Could be a good fit for: DevOps and IT operations teams that need ITSM workflows alongside incident management, particularly in regulated industries where compliance certifications and change management processes are non-negotiable.
8. Better Stack
Better Stack consolidates the observability and incident lifecycle If your team wants monitoring, logging, tracing, on-call, incident management, and status pages from a single vendor rather than assembling a multi-tool stack, Better Stack presents a unified option.
What it’s often known for:
Better Stack bundles uptime monitoring, log management, tracing, metrics, error tracking, on-call scheduling, incident management, and status pages into a single platform. For startups and mid-size teams that don’t want to manage a Datadog/PagerDuty/Statuspage stack separately, that consolidation could simplify the toolchain. On-call and alerting includes unlimited phone calls and SMS, and the platform provides automated postmortems built from the incident timeline and Slack conversation history.
Better Stack has also introduced a Slack-native AI SRE agent that investigates incidents by pulling context from your logs, metrics, traces, and errors, which strengthens the unified platform argument: the AI can draw on data across the full observability stack rather than being limited to the incident management layer alone.
The pricing model works in Better Stack’s favour for larger teams: the Responder license covers on-call engineers, but unlimited team members can access the telemetry platform (logs, metrics, dashboards) without additional per-user costs.
Could be a good fit for: Fast-moving SaaS startups and mid-size engineering teams that want to consolidate monitoring, observability, and incident management into a single vendor, and are comfortable trading depth of incident workflow automation for breadth of platform coverage.
How We Evaluated These Incident Management Platforms
Every platform in this list was assessed across five criteria that directly affect SRE team performance.
Evaluation CriterionHow We Assessed ItIntegration depthNative integrations with the monitoring and alerting tools most commonly used by SRE teams (Datadog, Prometheus, Grafana, AWS CloudWatch), not just total integration count.On-call managementFlexibility of scheduling, rotation, and escalation policy configuration, and whether on-call is included in the base price or requires a paid add-on.AI capabilitiesWhether AI features reduce time to resolution in practice or function primarily as postmortem summary generators. Whether they are included across all tiers or gated behind enterprise pricing, and whether they operate on the platform's own telemetry data.Post-incident learningDegree of automation in the retrospective workflow versus reliance on manual data entry. Whether action items are tracked to completion and recurrence of the same incident type is measurable.Pricing transparencyWhether a team can predict their annual cost from publicly available information without a sales conversation. Published per-user or flat-plan pricing scored higher. Sales-conversation-only pricing scored lowest.Edit Table
We also factored in platform ownership and continuity. Two platforms on this list have recently been acquired (FireHydrant by Freshworks, Squadcast by SolarWinds) and one is being sunset (Opsgenie by Atlassian). For teams making a multi-year tooling investment, those ownership changes are relevant to the evaluation and are flagged in the individual reviews.
Why SRE Teams Need Incident Response Training Software Alongside an Incident Management Platform
Every incident management platform reviewed above solves the same category of problem: managing the workflow of an incident after the alert fires. They route alerts, spin up channels, page engineers, and generate postmortem drafts. What none of them can do is build the coordination patterns, calm decision-making, and communication skills that determine whether your team resolves a Sev-1 in twelve minutes or three hours. These are skills, not settings.
This is where Uptime Labs fits. Rather than competing with the platforms above, Uptime Labs sits alongside them as a readiness layer. Teams run realistic incident simulations in a browser-based environment that mirrors production conditions, without any risk to live infrastructure. The drills cover the full spectrum of what real outages demand: technical diagnosis, stakeholder communication, and structured decision-making under time pressure.
After each drill, the platform measures performance across 40+ metrics in five competency categories, with targeted coaching from engineers with real incident management backgrounds. The results speak for themselves: Uptime Labs’ performance data shows a 35% reduction in incident resolution time across customers, with one customer reporting a 66% reduction. Those outcomes follow from the competency improvement. Teams that communicate more clearly, scope faster, and escalate with better judgement naturally resolve incidents in less time.
If you are investing in a new incident management platform, pair it with an incident response training programme that ensures your team can actually execute when it counts. See how Uptime Labs works, or read the complete guide to incident response training for a full overview of what to look for.
If your on-call rotation is already burning people out, adding a new tool is not the fix. Read How to Reduce On-Call Burnout in SRE Teams: 8 Structural Fixes for the structural changes that actually move the needle.
Peter Catack (Community Contributor)



