Incident Management Process: Steps, Cycles and What Really Happens

Ready to make incident response your competitive advantage?
See how Uptime Labs builds provable, scalable incident response capability across your financial services organisation.
The incident management process is the structured set of activities a team uses to detect, respond to, and recover from service disruptions. The goal is to restore normal service as quickly as possible while minimising impact on users and the business. The standard steps generally follow identification and detection, logging and declaration, categorisation and prioritisation, investigation and diagnosis, mitigation, resolution, communication, closure and post-incident review.
The textbook version of the incident management process is often useful. It gives teams a shared vocabulary, a default order of operations and a baseline to improve from. But anyone who has worked a real Sev-1 knows the textbook goes out the window fast. Most frameworks present these steps as a linear sequence. In practice, detection, mitigation, and communication run in parallel, not in sequence, and the teams who handle incidents well are the ones who have trained for that overlap.
This guide covers both: the standard incident management process flow, and what actually happens when a real incident unfolds. By the end, you will have a clear picture of each stage, where teams consistently break down, and how to build the kind of readiness that a Sev-1 actually demands.
What Is the Incident Management Process?
The incident management process is how a team moves from "something is wrong" to "the service is restored and we understand what happened." It covers the full arc: detecting the disruption, coordinating the response, restoring service and reviewing what the team learned.
Most organisations build their process from one of two traditions. Teams with an ITIL or ITSM background follow a structured lifecycle with formal logging, categorisation, and escalation tiers. SRE and DevOps teams tend toward a lighter framework built around SLOs, error budgets, and blameless review. The terminology differs, but both share a common skeleton: detect, respond, resolve, learn.
Where they diverge is in how rigidly they expect that skeleton to hold under pressure. The ITIL model assumes a process that can be followed as written. The SRE model assumes it will need to flex. What actually determines the outcome is neither the framework nor the documentation. It is whether the team has practised the process enough to run it when conditions are ambiguous and the stakes are real.
The Standard Incident Management Process Steps
The specifics vary by framework, but most incident management processes follow the same core stages. Here is what they look like in practice.

1. Identification and Detection
An incident enters the process when something signals that a service is degraded or disrupted. That signal can come from automated monitoring, a customer report, an internal engineer noticing anomalous behaviour, or an event management system raising an alert.
For SRE teams, this stage is often anchored to SLO-based alerting. When a service breaches its error budget threshold, that is an objective trigger to investigate rather than a subjective judgment call. The quality of detection directly shapes everything downstream: teams that catch issues before customers do have already bought themselves time. Teams relying on user reports have lost it.
2. Logging and Declaration
Every incident should be logged as a formal record from the moment it is identified. This step gets less attention than it deserves. The quality of the log (timestamps, affected services, initial observations, who was involved) directly determines the quality of the post-incident review later.
Declaration is the moment the team formally commits to running an incident response. It is a distinct act from logging, and many teams skip or delay it. When declaration is late, coordination starts late, communication is ad hoc, and the incident commander role never gets properly filled. Organisations that encourage early declaration, even when the situation is still ambiguous, consistently coordinate faster than those that wait for certainty.
3. Categorisation and Prioritisation
Priority is set by weighing two factors: impact (how many users are affected, how severely the service is degraded) and urgency (how time-sensitive the business risk is). A Sev-1 with full customer-facing downtime and a Sev-3 with a degraded internal tool require different response speeds, different roles, and different communication cadences.
Categorisation serves a longer-term purpose. Tagging incidents by affected service, failure domain, or contributing factor makes it possible to spot patterns across incidents over time. Categories that are too broad hide those patterns. Categories that are too granular create inconsistent data that no one trusts. The right balance is one the team reviews periodically, not one that is set once and forgotten.
4. Investigation and Diagnosis
ITIL treats investigation and diagnosis as a discrete step, but in practice it runs across most of the incident lifecycle. Engineers start forming hypotheses and testing them from the moment they look at a dashboard. Trying a potential fix and observing the result is itself part of the diagnostic process. The conventional model suggests that teams diagnose first and then repair, but real incidents rarely separate the two that cleanly.
This is the stage where the gap between the documented process and what actually happens opens widest. A team that has only read the incident response runbook and never practised diagnosis under pressure will slow here. The ability to hold multiple working theories, discard the ones that stop fitting, and coordinate across responders without losing context is a skill built through repetition, not documentation.
5. Mitigation and Resolution
Mitigation and resolution are distinct activities that teams frequently conflate. Mitigation is the temporary fix that stops customer impact: rolling back a deployment, failing over to a backup, or throttling traffic to a degraded service. Resolution is the work that addresses the underlying contributing factors so the same failure mode does not recur.
The pressure to close incidents quickly pushes teams to treat mitigation as resolution. The rollback works, the alerts clear, and the incident gets marked as resolved. Three weeks later, the same failure surfaces again. Keeping the two explicitly separate in the incident record forces the question: have we stopped the bleeding, or have we actually understood what went wrong?
6. Communication (Throughout)
Communication is not a step in the sequence. It runs in parallel from declaration to closure. Internal responders need shared context to coordinate. The business needs status updates to manage customer expectations. Leadership needs enough information to make resourcing decisions without pulling engineers off the technical response.
For SRE teams, this typically means maintaining a live incident channel, providing regular stakeholder updates at a defined cadence, and keeping the incident commander focused on coordination rather than diagnosis. The teams that struggle most with communication during incidents are not the ones lacking a template. They are the ones who have never practised deciding what to say, to whom, and how often while simultaneously trying to restore service.
7. Closure
Closure is the formal confirmation that the service is restored, the immediate fix is stable, and the incident record is complete. It sounds administrative, and it is, but skipping it creates problems downstream. Incidents that are left open clutter dashboards and erode trust in severity data. Incidents that are closed too early, before the fix is validated as stable, get reopened and double-counted.
The closure step should also capture whether the incident needs a formal post-incident review. Not every incident warrants one, but the decision should be deliberate rather than defaulting to "we'll get to it if we have time."
8. Post-Incident Review
The review is where the incident management process earns its long-term value. A good post-incident review is not about assigning blame or producing a checklist of corrective actions. It is about building a shared understanding of what happened, how the team responded, what made the situation confusing, and what the organisation can learn from it.
Reviews should be conducted soon enough that details are still fresh, and shared broadly enough that the learning reaches beyond the immediate responders. The most common failure mode is not a bad review. It is no review at all, because production pressure pushes the team straight into the next sprint.
Why Real Incidents Don't Follow the Steps
The linear model is a useful mental scaffold. It is not an accurate description of how incidents unfold. Here is what actually happens during a major incident:
- Detection and mitigation overlap. Engineers start trying fixes before the full scope is understood.
- Communication fragments. Threads split across Slack channels, calls, and direct messages while diagnosis is still in progress.
- Working theories get invalidated. New information arrives that forces the team back to investigation while mitigation is already underway.
- Escalation runs in parallel. Escalation decisions happen alongside triage, not after it.
None of this is dysfunction. It is the normal behaviour of skilled people working a complex problem under time pressure. The Incident Responder Workflow, developed for Uptime Labs by Beth Adele Long, captures this directly: outages rarely unfold in a series of tidy steps or phases. The process of responding to a real incident is exploratory, iterative, and inherently unpredictable.
The question is not whether your team will deviate from the documented process. They will. The question is whether they have practised enough to deviate well.
The Six Cycles of the Incident Management Process (How It Really Works)
The Uptime Labs Incident Responder Workflow, authored by Beth Adele Long, maps the incident management process as six overlapping cycles rather than a linear sequence. The model uses familiar terms (detection, mitigation, communication, resolution, review) but shows how they interact in practice: cycling back and forth, running in parallel, with transitions driven by judgment calls rather than objective state changes.
The standard steps from the previous section are still useful. Teams need a shared model to coordinate around, and the linear version serves that purpose. What the cyclical model adds is the recognition that real incidents do not stay inside the lines, and that a team's ability to handle that is what separates a process that works from one that only looks good in a wiki.
This is the diagram that replaces the linear flow chart above. Where the conventional model shows a straight line, this one shows the reality:
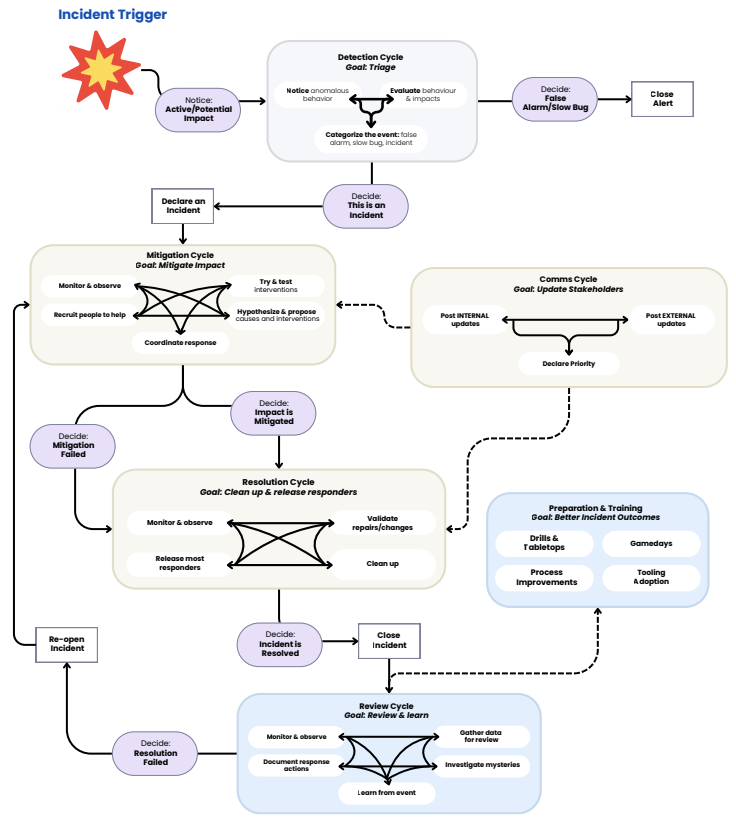
Cycle 1: Detection
The Detection Cycle's goal is triage. Alerts fire, a user reports degradation, or an engineer notices anomalous behaviour in a dashboard. What happens next is a judgment call: is this a false alarm, a slow burn bug that can wait, or an incident that needs to be declared now?
That categorisation decision is harder than it sounds. The signals are often ambiguous, the data is incomplete, and the cost of getting it wrong runs in both directions. Declare too early and you pull people off other work unnecessarily. Declare too late and coordination starts behind.
Cycle 2: Mitigation
The Mitigation Cycle begins the moment the team decides this is an incident, and its goal is to stop customer impact. The Incident Responder Workflow maps five activities that run simultaneously during this cycle: monitoring and observing, recruiting people to help, coordinating the response, testing interventions, and forming hypotheses about causes.
That simultaneity is the point. Mitigation is not one engineer fixing while others watch. It is a coordinated effort where multiple responders are working different threads at once, and the incident commander's job is to keep those threads from tangling. Making the right trade-offs during mitigation requires an understanding of both technical implications and business priorities.
For teams working through incident escalation decisions during this cycle, the question of when to escalate and who decides is one of the highest-stakes judgment calls in the process.
Cycle 3: Communication (Parallel)
The Comms Cycle runs in parallel with Mitigation and Resolution, and it involves a tension that most process documents ignore. If responders are too focused on communication, they cannot focus on mitigation. But if nobody is communicating outward, leadership feels stressed and confused, customers lose trust, and responders miss information flowing back from support and sales teams that could change the course of the investigation.
The information flow is bi-directional. The team is not just pushing status updates out. It is pulling context in: customer reports that clarify scope, leadership decisions about resourcing, and direction from stakeholders about business priorities. Finding the right cadence and content for both internal and external communication is one of the harder judgment calls in the process.
See our guide to incident management roles for how to separate communication ownership from technical leadership as your team scales.
Cycle 4: Resolution
The Resolution Cycle begins after impact is mitigated, and its goal is to clean up and release responders. This phase is generally less intense than Mitigation, but it carries its own risks. Responders may have put a shim in place to reduce customer impact but still need to understand the underlying issue. Changes made in the rush to mitigate may need to be rolled back, and the process of undoing those changes can introduce new problems.
The critical design requirement for this cycle is that it must accommodate failure. A fix that appeared to work can quietly degrade over hours. An incident that was closed can resurface. Process and tooling need to support re-escalation and re-opening without friction, because treating closure as final is how teams get caught out twice by the same incident.
Cycle 5: Review
The Review Cycle begins at closure, but it starts with something most process documents skip: responder recovery. Incidents are stressful, particularly high-severity or long-running ones. Recovery rituals, debriefs, and comp time are ways to mitigate the psychological and physiological impact on the people who just worked the incident. Teams that skip this step burn out their most experienced responders.
Immediately after closure is also the best time to gather artefacts that will support the formal review: screenshots of dashboards, log snippets, timeline reconstructions. These age out quickly, and teams that wait a week to start the review lose the raw material that makes it useful.
The review itself should focus on building a shared understanding of what happened, not on assigning blame or producing a checklist of fixes. Mysteries may remain. Messy incidents can be resolved without anyone fully understanding how they were triggered, and that is an honest finding, not a failure of the review process. The most common threat to the Review Cycle is not poor facilitation. It is production pressure compressing or eliminating the review entirely.
The Post-Incident Review Guide covers how to run reviews that produce understanding rather than just action items.
Cycle 6: Preparation and Training
This is the cycle most teams skip. It is also the one that determines how well every other cycle performs when a real incident hits.
Preparation is not a one-time activity. It is an ongoing cycle built from four activities: drills and tabletops, gamedays, tooling adoption, and process improvements. Each has trade-offs. Adversarial gamedays, where teams simulate incidents by injecting faults into staging or production, have the advantage of surprise and realism, but they are expensive to plan and orchestrate, and they risk triggering a real incident. Tabletop exercises are lower risk but lack the tempo and pressure of real incidents, which limits how much muscle memory they build.
Simulated drills sit between the two. They give responders a realistic environment with time pressure, ambiguity, and interpersonal dynamics, without the production risk of a gameday or the abstraction of a tabletop. The goal is not to test whether people have read the runbook. It is to build the judgment, coordination, and communication skills that hold up when conditions are uncertain.
Preparation also means seeking perspectives beyond the engineering team. Customer support, sales, legal, and leadership all play roles during major incidents. If your reliability and security teams do not collaborate closely, you risk developing conflicting processes for different classes of incidents.
What Does a Good Incident Management Process Flow Look Like?
A well-designed incident management process flow has three properties:
- It is readable under pressure. During a Sev-1, no one reads a 40-step flowchart. The flow needs to be simple enough to recall from memory and specific enough to be useful.
- It assigns ownership at each stage. Every stage should have a clear owner, whether that is the incident commander, the technical lead, or the communications role. When ownership is ambiguous, coordination gaps appear exactly when the team can least afford them.
- It accounts for parallel workstreams. A linear flow diagram misrepresents how incidents work. The best incident management process flows show detection, mitigation, and communication running simultaneously, with handoffs and decision points clearly marked.
The Uptime Labs Incident Management Process Flow Chart Template maps all six cycles with parallel workstreams, decision points, and role assignments. It is free to download.
The Biggest Gaps in Most Incident Management Processes
Teams that have a process documented but struggle in real incidents almost always share the same failure points:
- Declaration delay. Engineers spend several minutes trying to fix the problem before declaring an incident. By the time the IC is assigned, context is already fragmented.
- IC and technical lead collision. The person best positioned to diagnose the problem also tries to run communications and coordination. Diagnosis slows because attention is split, and stakeholders get sporadic updates because no one owns the communication cadence.
- Mitigation mistaken for resolution. The rollback works, the alerts clear, the incident is closed. Three weeks later, the same failure mode surfaces.
- Review without learning. The post-incident review produces a document that generates no shared understanding. The same contributing factors appear in the next major incident.
- No communication cadence. Stakeholders get one update at declaration and nothing until resolution. The business escalates. The engineering team gets interrupted mid-diagnosis.
- No preparation cycle. Here is the test that reveals whether your incident management process actually works: a P1 fires at 3 AM and the on-call engineer is a junior who joined six months ago. Do they know exactly what to do, or do they freeze? If the answer is "they would probably panic and message a senior engineer," your process exists in someone's head, not in your system.
How Does Uptime Labs Approach the Incident Management Process?
Uptime Labs builds the preparation cycle that most teams skip. The platform runs incident simulations in a safe, sandboxed environment that covers all six cycles of the incident management process: detection, mitigation, communication, resolution, review, and preparation.
Engineers work through high-fidelity simulations using the same tools they use in production (such as Slack, Grafana, etc.). Scenarios span operational outages, third-party failures, and security incidents. Each is designed to surface the behavioural challenges that process documentation alone cannot prepare teams for: stakeholder pressure, cross-team coordination breakdowns, and decision-making under uncertainty.
After each simulation, players receive a competency score across five categories: Identify Scope, Incident Mechanics, Internal Comms, External Comms, and Command Incident. Scores are tracked over time so teams and leadership can see measurable progress rather than relying on assumptions about readiness. A coaching debrief from Uptime Labs' incident management experts follows each session.
See how Uptime Labs builds incident readiness or download the Incident Responder Workflow to see the full cyclical model with decision points, parallel workstreams, and role assignments.
Related Guides
- Incident Management Roles Explained: When Each Is Needed: How the six core roles evolve as your team scales from three engineers to fifty.
- Incident Escalation Process: When, How, and Who Decides: A practical framework for escalation judgment, not just escalation tiers.
- Post-Incident Review Guide: Build Understanding, Not Just Fixes: How to run reviews that produce shared learning rather than action item lists.
- Incident Response Training: The Complete Guide: The four approaches to incident response training and how to measure what works.
- What Is an Incident Commander?: The role, the skills it requires, and when your team needs a dedicated IC.
- What Is MTTR?: What the metric actually measures, where it misleads, and what to track alongside it.
- Best Incident Management Platforms for SRE Teams (2026): A comparison of the platforms that support the incident management process at scale.
- Incident Management Process Flow Chart Template: The cyclical workflow model with decision points, parallel workstreams, and role assignments.
- Tabletop Exercises vs Live Incident Response Simulations: The trade-offs between the two most common approaches to incident preparation.
Incident Management Process: Frequently Asked Questions:
What are the steps in the incident management process?
The standard steps are identification and detection, logging and declaration, categorisation and prioritisation, investigation and diagnosis, mitigation, resolution, communication (which runs throughout), closure, and post-incident review.
What is the difference between mitigation and resolution in incident management?
Mitigation stops the immediate customer impact, for example by rolling back a deployment or failing over to a backup system. Resolution addresses the underlying contributing factors so the incident does not recur. Teams that conflate the two often close incidents before the underlying problem is understood, leading to repeated failures.
How does ITIL define the incident management process?
ITIL defines incident management as the practice of managing the lifecycle of all incidents, with the primary objective of returning IT services to users as quickly as possible. ITIL V4 is less prescriptive about specific process steps than V3 was, giving organisations more freedom to design processes that fit their context, while still emphasising clear roles, SLA adherence, and continuous improvement.
What is the most common failure point in the incident management process?
The preparation and training cycle. Most teams document their process but never practise it. When a real Sev-1 hits, engineers who have never run the process under pressure hesitate, escalate too late, or lose coordination across the response. Regular simulation training is the most direct way to close that gap.
Edward Page (Community Contributor)



.png)
