How to Reduce On-Call Burnout in SRE Teams: 8 Structural Fixes
Ready to make incident response your competitive advantage?
See how Uptime Labs builds provable, scalable incident response capability across your financial services organisation.
On-call burnout happens when rotation design, alert hygiene and engineer readiness are all broken at once. Fixing it therefore requires structural changes across scheduling, tooling and training - not just ‘better morale’. The most overlooked fix is giving junior engineers a safe place to practise before they carry the pager solo.65% of engineers reported experiencing burnout in the past year, according to the 2024 State of Engineering Management Report. For SRE and DevOps teams, the on-call rotation is where that burnout starts. On-call stress compounds quickly when rotations are poorly designed, alert noise is high and there is no automation to catch the easy stuff.But here is what most burnout guides miss: you can fix your schedule, tune your alerts and still have your seniors getting paged at 3 AM because a junior engineer escalated something they did not know how to handle. That is not an alerting problem. That is a readiness problem.This guide covers eight structural fixes that address both alerting and readiness. Work through them in order: each one is designed to build on the last.
Why Does On-Call Burnout Happen in SRE Teams?
Before fixing your on-call rotation, it helps to understand why most rotations break down. The core problem is rarely the concept of being on-call. Instead, it is the accumulation of bad patterns that pushes on-call engineers towards burnout.The most common patterns are:
- Alert fatigue. Research shows teams receive over 2,000 alerts weekly, with only 3% needing immediate action, leading to missed critical alerts and prolonged outages.
- Unbalanced rotations. When fewer than five engineers share 24/7 coverage, each person gets paged far more often than they should. This accelerates fatigue and creates fragile single points of knowledge.
- No separation between on-call and project work. Google's SRE philosophy explicitly reserves at least 50% of SRE time for project work. When on-call bleeds into sprint goals and delivery timelines, engineers feel perpetually behind, even when they did everything right.
- Undertrained junior engineers. Junior engineers feel more pressure because they lack both deep systems knowledge and the confidence to challenge AI recommendations or to resolve incidents independently.
46% of SREs reported responding to more than 5 incidents in the last 30 days, while 23% handled between 6-10 incidents. At that level, the load can quickly lead to burnout when combined with other engineering responsibilities.

Source: https://www.catchpoint.com/asset/2025-sre-reportThe fixes below address each of these failure modes directly.
The 8 Structural Ways to Reduce On-Call Burnout
1. Right-Size Your On-Call Rotation
The most basic lever you have is rotation frequency. Monthly shifts concentrate stress. Weekly rotation provides a good balance for most teams. The goal is to keep each engineer's on-call window predictable and recoverable.Team sizing determines sustainability. Fewer than four engineers creates excessive rotation frequency. Fewer than three makes coverage impossible during vacations. Grow teams before expanding on-call scope.If your team is too small to run a healthy rotation, resist the temptation to just push through. The cost of burning out a senior SRE, when considering loss of institutional knowledge and rehiring time - is far higher than the cost of expanding the rotation.On-call schedule tip: Engineers need advance notice of on-call schedules, a minimum of two weeks, at least but ideally one month. Predictable schedules enable personal planning, reduce anxiety about unexpected responsibility, and allow time to arrange coverage swaps when conflicts arise.
2. Adopt a Follow-the-Sun Model (If Your Team Is Large Enough)
For teams with engineers across multiple time zones, follow-the-sun (FTS) scheduling is the most direct way to eliminate after-hours paging. With three sites, FTS reduces on-call duration by extending productive hours around the clock, translating to faster acknowledgment times and lower fatigue risk across the entire rotation.
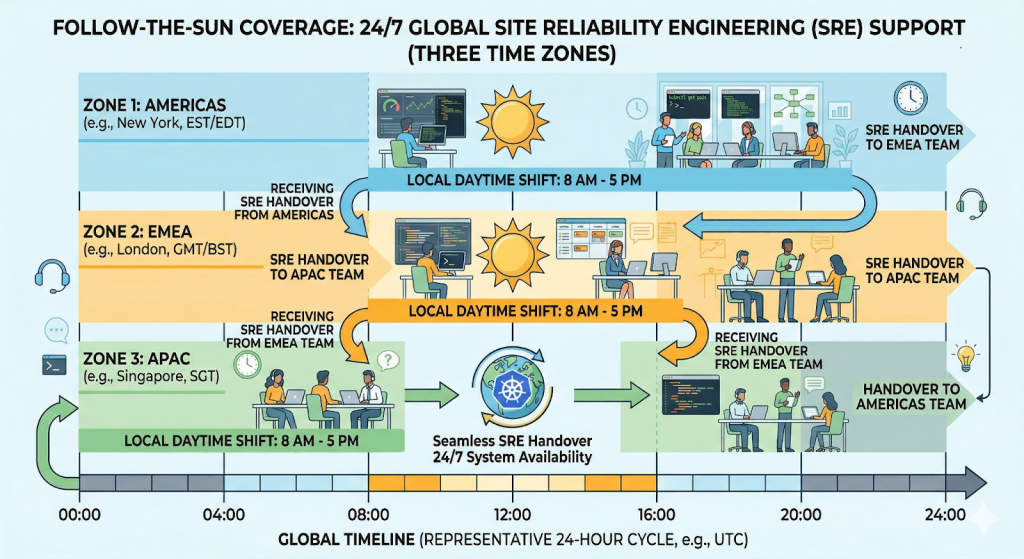
The catch is that FTS has hard prerequisites. FTS demands a minimum team size of 9-15 engineers across at least 3 locations, with 3-5 per location. If engineers do not trust the incoming region to deliver the same quality of response, resentment builds. Trust between teams is essential.If you cannot meet those requirements today, a tiered primary/secondary model with clear escalation paths is a more realistic starting point. Modern teams benefit from rotation transparency: everyone should know exactly who is on call, who backs them up, and how to escalate. Engineers are less likely to feel always on’ when on-call windows are well-defined, handoffs are explicit, and escalation paths are known in advance.
3. Fix Your Alert Hygiene Before Anything Else
Alert fatigue is the most direct driver of on-call burnout, and it is a systems design problem not a morale problem - an important distinction. A 2025 study by Splunk showed 73% of organisations experienced outages linked to ignored alerts. When engineers start treating pages as background noise because a significant portion are not actionable, you have created the conditions for a missed P1.The Google SRE Workbook recommends a maximum of 2 actionable incidents per shift as a sustainable baseline. If your team is consistently seeing 8-10, you do not have an on-call problem - you have an alerting problem.A healthy alerting system has fewer than 10% non-actionable alerts as a warning sign. If fewer than 30% of your alerts lead to a meaningful action, start your burnout fix here before your next on-call rotation begins.
4. Build Runbooks That Actually Answer ‘What Do I Do Right Now?’
Engineers who wake up at 3 AM without documented procedures are forced to wing it under pressure. This leads to longer MTTR, more stress and decisions made without context.A runbook is not a system architecture document. It should answer: what do I do right now? - not: what is the architectural history of this service?Runbooks reduce MTTR, lower the cognitive load on on-call engineers, and reduce the fear that makes burnout worse. They are especially valuable for junior engineers or anyone onboarded into a complex system quickly.Build runbooks for your five most common incident types first. For each one, include specific commands, specific dashboards, and specific escalation contacts (such as the incident commander). Review and update them after every post-mortem. A runbook that has not been touched in six months is a liability.For a deeper look at runbook structure and best practices, see our guide on incident response runbooks.
5. Enforce a Hard Boundary Between On-Call and Project Work
On-call engineers carry a significant cognitive load even during quiet shifts. On-call engineers typically allocate 30-40% of their bandwidth during an on-call period to incident responsibilities. Expecting full sprint delivery on top of that is how you burn people out silently.The fix is structural, not cultural. Reserve dedicated project time that is protected from on-call interruptions. Recall Google’s SRE philosophy -when on-call bleeds into sprint goals and delivery timelines, engineers feel perpetually behind - even when they did everything right.Explicitly build recovery time into your process. Automatic days off after severe incidents and lighter workload expectations the week following on-call duty are both valid approaches. Teams that treat recovery as part of the on-call process are more likely to keep engineers engaged and willing to rotate on call over the long term.
6. Formalise Your Handoffs
Handoffs fail when they rely on memory. A verbal ‘it was a quiet week’ at shift changeover is not a handoff. It is an invitation for the incoming engineer to rediscover everything the outgoing engineer already knew.A complete shift handoff should cover:
- Active incidents: current status, severity, and next steps
- Alerts that fired but were not actioned, and why
- Any system changes made during the shift
- Anything the incoming engineer should watch closely
The handoff summary should be posted to a shared Slack or Teams channel visible to the entire SRE organisation, so context is never trapped in a single person's head.Structured handoffs reduce the cognitive overhead of starting a shift from zero. They also surface patterns across rotations (such as recurring alerts, repeated escalations, knowledge gaps) that would otherwise stay invisible until they cause a major incident.
7. Compensate On-Call Fairly and Transparently
On-call is work. It disrupts sleep, social plans, and recovery time. Engineering teams that treat on-call as an informal obligation without compensation, time back, or formal acknowledgment send a clear message: your time outside business hours does not matter.What matters is consistency and transparency. Engineers are far more willing to participate in on-call when they know the programme is fair and the organisation recognises the burden.Compensation models vary. Some organisations pay a weekly stipend for availability regardless of incidents. Others provide compensatory time off after heavy shifts. Fair pay, meaningful recovery time, and strong wellness practices help responders manage stress and maintain long-term engagement. The specific model matters less than whether engineers trust that it is applied consistently.If your best engineers feel like button-pushers, they will go somewhere else. Burnout and boredom drive attrition, and losing a senior developer can mean months of rehiring and retraining for an impact-driving role.
8. Train Junior Engineers Before They Carry the Pager
Junior engineer incident response training is the fix most teams skip and the reason burnout persists even after everything else is in place.When a junior engineer escalates an incident they cannot resolve, the senior SRE on backup gets paged. That senior loses sleep, carries the cognitive load, and absorbs the stress that should have been handled one tier down. Multiply that across a rotation and you have a structural burnout machine, regardless of how good your schedule and alert hygiene are.Google's SRE approach focuses on competency and gradual exposure rather than an arbitrary quota of incidents. Engineers do not go primary on-call until they have completed a structured progression: reading historical postmortems, standard shadowing, and finally, "reverse shadowing" (where the junior engineer drives the incident while a senior SRE silently observes as a safety net). This reduces anticipatory anxiety - which accounts for the vast majority of on-call stress - builds confidence through practice, and creates muscle memory for high-pressure situations.The problem with shadow rotations alone is that real incidents are unpredictable. A junior engineer can shadow ten quiet shifts and still be completely unprepared for a Sev-1 database failure. That is where simulation training fills the gap.An upfront investment of a few weeks of structured, simulated training prevents months of team-wide burnout and poor incident response.This is where Uptime Labs comes in. Uptime Labs' Incident Response training simulations give junior engineers a realistic, safe environment to practise incident response before they face a live customer-impacting outage. Engineers work through high-fidelity simulations using the same tools they use in production (such as Slack, Grafana, etc.) so the first time they face a Sev-1, it is not actually the first time.The result: junior engineers join the rotation ready to handle incidents independently. Senior engineers stop absorbing escalations they should not be receiving. On-call burnout drops because the load is genuinely distributed, not just scheduled that way on paper.67% of SREs report not having enough time to spend on technical training (SRE Report 2025, Catchpoint). Uptime Labs removes the time barrier by making training asynchronous, gamified, and measurable - so it actually happens.
How to Measure Whether Your On-Call Burnout Fixes Are Working
Gut feelings about on-call health are unreliable. Track these four metrics to know whether your interventions are having a real effect:
- MTTR (Mean Time to Recovery). From alert to resolution - a controversial statistic for many engineers, but worth keeping an eye on.
- Alert-to-action ratio. The percentage of alerts that result in a meaningful response. Target 30-50% actionable.
- Escalation rate. How often primary on-call engineers escalate to secondary or senior backup. A falling escalation rate is a direct signal that junior engineer readiness is improving.
- On-call satisfaction score. Run a short anonymous survey after every rotation. Ask one question: "How sustainable was this on-call shift?" Track the trend.
Burnout indicators from anonymous surveys should show sustainable stress levels. Turnover rates for engineers in on-call rotation should match or beat the organisation average. On-call-related attrition should approach zero.
Common Mistakes to Avoid
- Fixing the schedule without fixing alerts. A better rotation cadence on top of 2,000 weekly alerts still produces burnout.
- Writing runbooks and never updating them. A runbook that does not reflect the current system is worse than no runbook, masking unpreparedness across teams.
- Treating shadow rotations as sufficient training. Shadowing quiet shifts does not prepare engineers for high-severity incidents.
- Compensating on-call informally. "We appreciate you" is not a compensation model. Undocumented recognition breeds resentment.
- Skipping blameless post-mortems. 28% of SREs feel more stressed after incidents are resolved. Factors like a lack of a blameless culture may contribute to this lingering stress (SRE Report 2025, Catchpoint).
FAQs: On-Call Burnout
What causes on-call burnout in SRE teams?
On-call burnout is caused by a combination of structural failures: too-frequent rotation due to small team size, high alert noise with low actionability, no protected project time, poor handoff discipline, and undertrained junior engineers who escalate incidents to seniors unnecessarily. Fixing one factor without addressing the others rarely produces lasting improvement.
How many engineers do you need to run a sustainable on-call rotation?
Fewer than four engineers creates excessive rotation frequency. Fewer than three makes coverage impossible during vacations. Grow the team before expanding on-call scope. For follow-the-sun coverage, you need a minimum of 9-15 engineers across at least three locations.
How does simulation training reduce on-call burnout?
Structured incident response training using high fidelity simulations reduces burnout by building junior engineer confidence before they carry the pager independently. When junior engineers can handle incidents without escalating to seniors, the on-call burden distributes as intended. Uptime Labs' incident response simulations use high-fidelity, tool-integrated simulations to build that readiness in a safe environment - so engineers arrive on rotation ready to respond, not ready to panic.
What is a healthy alert-to-action ratio for on-call teams?
If fewer than 10% of your alerts are actionable, you likely have significant noise. Healthy systems typically achieve 30-50% actionable rates. Use this as a benchmark when auditing your alerting configuration.
How do you measure on-call burnout before it causes attrition?
Track escalation rates, MTTR trends, and alert-to-action ratios alongside a short anonymous post-rotation survey. Patterns like after-hours alerts, uneven incident distribution, and repeated interruptions can accumulate into fatigue or burnout, leaving responders with a lingering uneasiness that another alert could arrive at any moment. Catching those patterns early, before an engineer quits, is the goal.
Is on-call burnout related to the on-call schedule alone?
No. The core problem is rarely the concept of being on-call - it is the accumulation of bad patterns that make it unbearable. Schedule design is one lever. Alert hygiene, runbook quality, engineer readiness, and recovery time all contribute.
Peter Catack (Community Contributor)


