Incident Response Training: The Complete Guide for Engineering Teams
Ready to make incident response your competitive advantage?
See how Uptime Labs builds provable, scalable incident response capability across your financial services organisation.
Incident response training is the structured practice of incident response skills, away from live, (potentially customer-impacting) outages. Engineering teams that train regularly build muscle memory, communication habits, and diagnostic speed, helping reduce MTTR when real incidents occur. It is the difference between a team that has a plan and one that can actually execute it under pressure.Most engineering teams only practise incident response during actual incidents. That is the problem this guide addresses. By the end, you will know what effective incident response training looks like, how the main approaches compare, how to build a programme that produces measurable improvement and what to measure to prove it is working.This guide is for the engineers who carry the pager and for engineering leaders responsible for their readiness.
What Is Incident Response Training? (And Why Engineering Teams Need It)
Incident response training is the deliberate practice of the skills, processes and communication patterns required to detect, triage, contain, and resolve production incidents, conducted in a controlled environment before those skills may be required by a live outage.The obvious case for incident response training starts with cost. Outage costs per minute range from $3,637 for mid-market companies to $23,750 for large enterprises, according to a 2024 EMA study. Every minute of extended MTTR has a direct dollar value attached.
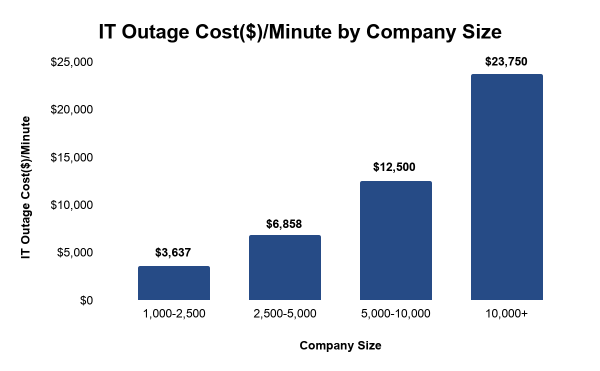
Source: IT outages: 2024 costs and containment by EMA ResearchSystems fail. When they do, the outcome depends on the people responding: how quickly they acknowledge, how accurately they diagnose, how clearly they communicate, and whether they escalate at the right moment. These are the capabilities that determine whether a failure becomes a ten-minute incident or a two-hour outage. Training builds those capabilities before they are needed.
Compliance Requirements for Incident Response Training (DORA & FCA)
For engineering teams in financial services or critical infrastructure, incident response training is no longer discretionary. It is a compliance requirement.DORA (the EU's Digital Operational Resilience Act) requires financial entities to maintain ICT risk management frameworks that include digital operational resilience testing. In practice, that means demonstrating that your team can respond to incidents through structured scenario exercises, not just that you have a plan on paper.In the UK, the FCA's operational resilience framework carries equivalent weight. Firms must identify vulnerabilities through testing and conduct lessons-learnt exercises that demonstrate their ability to respond to and recover from disruptions. The expectation is active, tested readiness, not documented intent.If your organisation falls under either framework, the engineering team's ability to prove that incident response capability has been tested and measured forms part of the compliance case. This is one of the drivers behind the shift from ad-hoc training to structured programmes with auditable outcomes.
Why the Need for Incident Response Training Is Growing
Modern distributed systems fail in ways that are harder to diagnose than monolithic architectures. Microservices, third-party dependencies, and multi-cloud deployments mean that a single incident can span dozens of services, with no obvious single point of failure. Smaller teams are carrying more services. The complexity of what engineers are expected to respond to has grown faster than the training available to prepare them for it.The result is that even experienced engineers can find themselves navigating an unfamiliar failure mode under pressure, in front of stakeholders who want answers. Structured training exists to close that gap.For a deeper look at how on-call pressure compounds without structured preparation, read Reduce On-Call Burnout: A Practical Guide for Engineering Teams.
Why On-the-Job Incident Response Training Fails
The default approach to incident response training is no training at all. Engineers learn by responding to live, customer-impacting outages. The assumption is that experience accumulates over time, and eventually, engineers develop the instincts they need.This assumption has three specific failure modes.
- Slow acknowledgement. Without practised triage habits, engineers spend the first minutes of an incident confirming that something is actually wrong, finding the right runbook, and working out who else to loop in. Those minutes are expensive. The escalation process breaks down before any technical diagnosis has even started. Engineers either escalate too early or hold too long, and without practised judgment, both mistakes compound. For a structured framework on when and how to escalate, see the incident escalation process guide.
- Poor communication under pressure. Incident communication is a skill. Declaring severity, writing stakeholder updates, managing a channel and handing off to the next responder all require habits that do not form automatically. Under stress, communication is the first thing to collapse.
- Juniors who cannot go on-call. Without a safe environment to practise, junior engineers cannot be trusted with independent on-call rotations until they have accumulated enough live incident experience to be confident. That experience takes months to accrue, during which senior engineers absorb the full on-call burden.
Google's SRE book makes this point explicitly: the way to build incident response capability is to practise hypothetical outages, not to wait for real ones. A written incident response plan is not the same as a team that can execute it. The gap between the two is what training closes.
Incident Response Training Approaches Compared
Not all incident response training is equivalent. The four main approaches differ significantly in fidelity, cost, and what they actually test.
Incident Response Simulation
High-fidelity incident response simulations place engineers inside a realistic, safe-environment replica of a production incident. They use the same tools they use on a real shift (Slack, Grafana, monitoring dashboards), respond to a realistic failure scenario, and are scored on specific skills: time to acknowledge, diagnostic accuracy, communication clarity and escalation decisions.The key characteristic is that engineers must actually do the work, not just discuss it. They run queries, read logs, form hypotheses, validate fixes and manage stakeholder pressure simultaneously. The simulation tests performance under conditions that resemble the real thing.This is the approach Uptime Labs is built on. Simulations run in a browser-based environment with no production access required and no integration overhead.
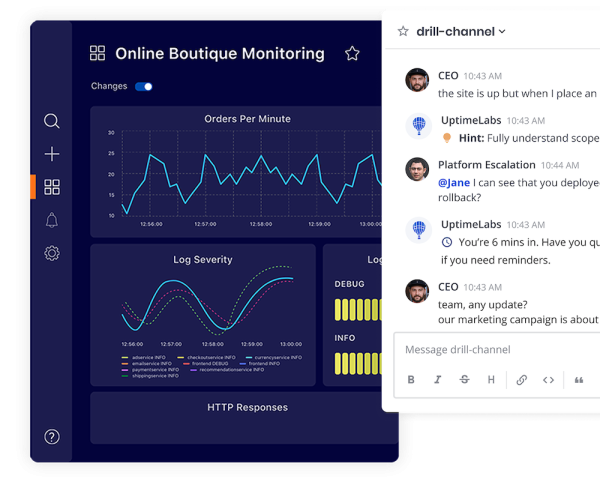
Best for: SRE teams, on-call readiness, measurable skill development, junior engineer onboarding.
Tabletop Exercises
A tabletop exercise is a discussion-based walkthrough of an incident scenario. Participants talk through what they would do at each stage, without executing any of it. A facilitator presents the scenario, and the team reasons through their response together.Tabletops are low-cost and easy to run. They are genuinely useful for validating a new incident response plan, aligning cross-functional stakeholders on roles and responsibilities, and surfacing process gaps that nobody had noticed. They may act as a good complement to simulation.Their ceiling is fidelity. Talking through a scenario and actually executing it under pressure are different cognitive and emotional experiences. A team can pass a tabletop and still fumble the real thing. For a direct comparison of when each approach is appropriate, see Tabletop vs Live Incident Response: Which Does Your Team Actually Need?.Best for: Cross-functional alignment, new plan validation, non-technical stakeholders.
Game Days and Chaos Engineering
Game days originated at Amazon and were formalised at Google as DiRT (Disaster Recovery Testing). The format involves deliberately triggering failure conditions in a controlled environment to test how systems and teams respond. Chaos engineering tools like Gremlin extend this by injecting faults into production or staging infrastructure to validate system resilience.The critical distinction is what is being tested. Chaos engineering tests whether the system degrades gracefully. It answers the question: does the architecture hold up under fault conditions? It does not test whether the on-call engineer can triage the incident, communicate clearly with stakeholders or make the right escalation call under pressure.An SRE team running chaos experiments may have high confidence in their infrastructure resilience and low readiness in their human response capability. These are separate problems that require separate solutions.For a full breakdown of where chaos engineering ends, and human readiness training begins, read Chaos Engineering Tools vs Incident Response Simulations and What Is Chaos Engineering?.Best for: System resilience validation, infrastructure confidence-building.Not a substitute for: Human readiness training.
Certification Programmes (SANS, CISA, EC-Council)
Certification programmes like SANS GCIA, CISA, and EC-Council's ECIH teach incident response frameworks, security fundamentals, and compliance-aligned processes. They test knowledge of how incident response should work.For SRE and DevOps teams, they address the wrong problem. A certification tests whether an engineer can answer questions about incident response methodology. It does not test whether that engineer can triage a cascading microservices failure at 2am while the CEO is asking for updates in Slack.Certifications are genuinely valuable for security operations roles, compliance functions, and engineers who need a structured foundation in security incident response. They are not a substitute for practising the skills in conditions that resemble real incidents.Best for: Security operations, compliance roles, baseline framework knowledge.
Which Incident Response Training Approach Fits Your Team?
Most mature engineering teams use simulation as the primary training method and chaos engineering for system validation, and certifications.
What Skills Do Teams Need For Effective Incident Response?
Incident response is not one skill. It is a cluster of distinct capabilities that must work in parallel, under pressure, often with incomplete information.
Technical Diagnostic Skills
The core technical job in an incident is fast & accurate diagnosis under uncertainty. The specific skills that training should build:
- Scoping the blast radius to understand which services are affected, which are not and how confident are you in that assessment.
- Correlating signals across logs, metrics, and traces from multiple observability sources.
- Forming and testing hypotheses about root cause without anchoring on the first plausible explanation.
- Validating the fix before declaring resolution, not just deploying it and hoping.
Engineers who train these skills develop faster and more accurate diagnostic reasoning. Engineers who only practise during live incidents develop habits shaped by stress and time pressure that are not always good.
Communication and Coordination
Poor communication during an incident extends MTTR independently of the technical work. A team that diagnoses the problem in ten minutes but takes another forty to communicate and coordinate the fix has a communication problem, not a technical one. The specific skills:
- Declaring severity at the right level, without under- or over-escalating.
- Writing the first stakeholder update that is accurate, appropriately scoped, and sent within minutes, not after the investigation is complete.
- Managing the incident channel so it stays structured and useful rather than filling with noise.
- Handing off cleanly at shift change or when escalating to a specialist, without losing context.
These are learned behaviours. They do not form automatically, and under stress, communication is the first thing to collapse.
Decision-Making Under Pressure
The hardest decisions in an incident are the ones made with incomplete information. Training builds the decision-making habits that hold up under those conditions. The specific decisions:
- Containment versus root cause - knowing when to stop the bleeding before understanding why it started.
- Rollback versus forward fix - weighing the risk of reverting against the risk of pushing a fix under pressure.
- Escalate versus keep digging - recognising when a problem is beyond your current scope before you have wasted twenty minutes proving it.
- Maintaining clear thinking under social pressure - cognitive bias, fatigue and a room full of people waiting for an answer all degrade decision quality. Training builds resistance to those effects.
For a breakdown of the roles that carry these responsibilities during a live incident, download our free Incident Roles & Responsibilities guide.
How to Build an Incident Response Training Programme
A structured incident response training programme should include the following four stages.
Stage 1: Knowledge Transfer
Before an engineer can respond effectively to an incident, they need accurate mental models of the systems they are responsible for. This means architecture walkthroughs, dependency mapping, and a genuine understanding of blast radius for the services they own.Post-incident reviews are the most valuable learning material at this stage, not runbooks. A well-written post-incident review shows how a real failure unfolded, what signals were visible, what decisions were made and why, and what could have gone faster. Reading five post-incident reviews from your own systems teaches more about how those systems fail than any runbook.The goal of Stage 1 is to build the mental models that simulations will test. An engineer who does not understand how their services connect will not diagnose incidents effectively, regardless of how much they practise.
Stage 2: Shadow Rotations
Shadow rotations bridge the gap between theoretical knowledge and live practice. The shadow engineer observes an experienced on-call engineer handling real incidents and simulated drills, without carrying independent responsibility.The shadow is not passive. They should produce written debriefs after each session, document questions that arose, and contribute runbook updates based on what they observed. The output of a shadow rotation is a more accurate mental model of what on-call actually looks like, and the beginning of escalation judgment.Escalation judgment (knowing when a problem is beyond your current scope and needs another set of eyes) is one of the hardest skills to develop without structured practice. Shadow rotations build it in a low-stakes context. For more on how escalation decisions work in practice, see Incident Escalation Process: When, How, and Who Decides.Structured shadow rotations also reduce senior engineer burnout. The goal is to build an independent on-call capability, not to extend the period during which seniors carry all the weight. For more on this, read Reduce On-Call Burnout: A Practical Guide for Engineering Teams.
Stage 3: Simulation Practice
Simulation is where skills are tested and developed in a safe environment. Engineers respond to realistic incident scenarios using the tools they use on real shifts, without risking production.A monthly simulation cadence is a practical standard for most teams. Each drill should target specific competency gaps identified in previous sessions or in recent post-incident reviews. A drill that is not connected to a real competency gap will not produce measurable improvement.Uptime Labs provides browser-based simulation environments built for this stage: realistic toolchain integrations (Slack-adjacent, Grafana), structured scoring across individual competencies, and expert coaching after each session.For a deep dive on applying this model specifically to junior engineers entering on-call rotations, see Incident Response Training for Junior Engineers.
Stage 4: Readiness Criteria
Readiness is not a feeling. It is a set of objective, measurable criteria that an engineer meets before carrying independent on-call responsibility.Role-based readiness criteria look different for an incident commander and a specialist on-call engineer. An incident commander needs to demonstrate clear severity declaration, effective stakeholder communication and confident escalation decisions. A specialist on-call engineer needs to demonstrate diagnostic accuracy and containment speed for the services they own.Within each role, proficiency develops progressively. An engineer might reach a professional level in diagnostic skills but still be at an associate level in incident command. Role-based readiness criteria make that gap visible and give the engineer a specific development path rather than a vague instruction to get better at incidents.Tracking proficiency over time, across multiple simulation sessions, is what makes readiness criteria meaningful. A single good drill does not prove readiness. A consistent upward trend across five sessions does.
Measuring Incident Response Readiness
Subjective readiness assessments fail. "I think the team is ready" is not a measurement. It is a guess, and it tends to be optimistic until a painful live incident proves otherwise.The instinct is to reach for time-based metrics: MTTA, MTTD, MTTR. These CAN BE useful outcome indicators. If your MTTR is trending down over six months, something maybe working (though worth noting that these metrics need to be contextualised).But a single MTTR number tells you how long an incident took. It does not tell you why it took that long or what to train next. Two incidents with identical MTTR can have completely different failure profiles underneath.What actually drives improvement is measuring the specific competencies that incidents demand. The categories that matter:
- Scoping and diagnosis - can the engineer accurately identify what is affected, qualify the severity and use metrics as evidence rather than assumption?
- Incident mechanics - are records created promptly, criticality formally assigned and the investigation structured rather than ad hoc?
- Internal communication - are updates timely, clear, and frequent? Is the investigation team formed quickly? Is escalation happening when it should?
- External communication - are stakeholders and customers informed within minutes, not after the fact? Are resolution updates cross-checked with the team before going out?
- Incident command - is someone taking clear ownership, timeboxing actions, managing the team and prioritising restoration over root cause analysis during the incident?
These competencies are what set a team that resolves incidents quickly apart from one that sometimes gets lucky. Time-based metrics are the scoreboard. Competency measurement is the coaching feedback that tells you how to move the score.Uptime Labs tracks performance across 40+ metrics mapped to these competency categories and plots each engineer's proficiency on a radar chart after every session. Over multiple drills, the chart shows where skills are developing and where gaps persist, giving engineering leaders specific, actionable data rather than a single number.
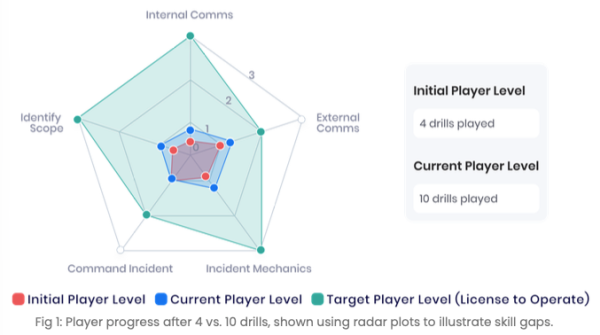
Incident Response Training: The Continuous Improvement Loop
Training programmes that run drills without connecting them to real incident data plateau quickly. The drills become familiar, the scenarios stop reflecting the team's actual failure modes, and improvement grinds to a halt.The continuous improvement loop looks like this: train, respond to real incidents, run post-incident reviews, feed the findings back into training scenarios, train again. Each cycle should be tighter and more targeted than the last.Post-incident reviews are the input that keeps training relevant. If your last three PIRs all flagged slow severity declaration, the next drill should open with an ambiguous alert that forces the engineer to make the severity call within the first two minutes. If post-incident data shows that internal communication consistently breaks down during multi-team escalations, the next simulation should specifically target that competency. The drill should test what the real incident exposed, not what the team is already comfortable with.The connection between training data and incident data is the most underused lever in most engineering organisations. If the competencies that score lowest in simulations are the same ones that break down in real incidents, that is a signal that training is targeting the right areas and needs to continue. If they are different, that is also a signal: either the simulations are not realistic enough, or the real incidents are exposing failure modes the training programme has not addressed yet.This loop is what separates a training programme that produces genuine readiness from one that produces completion certificates. The enterprise incident response plan guide covers how to build the process infrastructure that makes this loop work at scale.
Incident Response Training Challenges (And How to Solve Them)
- Lack of time. A single hour of downtime costs more than a month of regular simulation sessions. The team that says it doesn't have time for training is diverting that time on preventable incidents.
- Senior engineer availability. The goal of a structured training programme is to reduce dependency on senior engineers, not increase it. Every junior engineer who reaches independent on-call readiness through structured training is one fewer escalation landing on a senior at 3am. The short-term investment reduces the long-term burden.
- Tabletop fatigue. Tabletops test plans. Simulation tests people. If your tabletop exercises are not producing improvement in live incident performance, it is because discussing what you would do is not the same as building the habits you need to do it. The two approaches are not interchangeable.
- Production risk concerns. Simulation environments exist precisely for this reason. Uptime Labs runs entirely in a separate environment with no production access required. Engineers make mistakes, learn from them and build confidence without any customer impact.
- Measurement gaps. If you cannot measure it, you cannot improve it. Subjective assessments of team readiness are consistently optimistic until a painful incident proves otherwise. Competency-level scoring after each simulation, tracked over time across specific skill categories, is what makes improvement visible and defensible to senior leadership.
Evaluating an Incident Response Training Platform
Once the decision to invest in structured training is made, the next question is which platform to build it on. Not all platforms test the same things, and the differences matter. Six questions to ask any vendor before committing:
- Does the simulation feel like a real incident, or is it a multiple-choice quiz?
- Real incident response requires engineers to use actual tools, read real signals, and make real decisions under time pressure. A platform that presents scenarios as structured questions is not building the muscle memory that matters.
- Avoid: Platforms that deliver scenarios as written prompts, slide-based walkthroughs or multiple-choice assessments.
- Look for: Browser-based environments where engineers interact with realistic monitoring dashboards, log outputs, communication channels and external stakeholder pressure in real time.
- Does training require production access or significant integration work?
- If setup requires production access, custom infrastructure configuration, or significant engineering time, the platform will never be used consistently. Setup friction kills adoption.
- Avoid: Platforms that require production access, custom configuration or engineering time ahead of the first session.
- Look for: A self-contained, browser-based environment with no integration overhead. Engineers should be able to log in and start a simulation immediately.
- Does the platform measure specific competencies, or just track completion?
- Completion tracking tells you that engineers showed up. Competency-level scoring tells you whether they improved across the capabilities that actually determine incident outcomes. These are different measurements with different values.
- Avoid: Platforms that only report pass/fail results, completion percentages, or aggregate team scores without individual breakdown.
- Look for: Scoring across specific competency categories (scoping, communication, incident command) tracked per engineer over time, with visible progression through defined proficiency levels.
- Can training paths be customised by role?
- An incident commander needs different training from a specialist on-call engineer. A platform that treats all engineers as identical is not reflecting how incident response actually works.
- Avoid: One-size-fits-all training paths where every engineer runs the same drills regardless of their role in the incident response structure.
- Look for: Role-based training with different scenarios, skill targets, and readiness criteria for incident commanders, on-call engineers, and other roles in your response framework.
- Is there expert coaching, or just automated scoring?
- Automated scoring identifies what happened. Expert coaching explains why it happened and how to improve. For engineers building new skills, the coaching is often more valuable than the score.
- Avoid: Platforms that rely solely on automated feedback or self-assessment with no human input.
- Look for: Coaching from practitioners with real incident management experience who review individual sessions and provide targeted, actionable feedback.
- Does the simulation use the tools your team already works with?
- Fidelity depends on familiarity. Training in an unfamiliar interface builds habits for that interface, not for your actual production environment.
- Avoid: Platforms that use proprietary interfaces bearing no resemblance to your team's actual toolchain.
- Look for: Simulations that replicate the tools your team uses daily, including Slack,, Grafana, and terminal interfaces.
Incident Response Training in Action: The Uptime Labs Approach
Here is what a simulation session looks like in practice:An engineering team at a mid-size e-commerce company logs into Uptime Labs. No setup. No integration work. The browser-based environment shows a scenario: orders per minute have dropped sharply, error rates are climbing, and the CEO has already messaged the incident channel to ask what is happening.The on-call engineer starts working. They check the monitoring dashboard, correlate the error spike with a recent deployment, form a hypothesis, validate it against the logs, and start communicating with stakeholders while the investigation continues. The CEO's messages keep coming, requiring urgent resolution. A fellow engineer in the channel suggests it cannot be the deployment. The engineer has to decide whether to trust that instinct - or keep following the evidence.The whole session runs in a Slack-adjacent interface, with real monitoring dashboards, real log data and real stakeholder pressure. No production systems are involved. And again - no integration is required.When the session ends, Uptime Labs scores the engineer across the competency categories covered earlier in this guide and plots their proficiency on a radar chart. An expert coach with extensive incident management experience reviews the session and provides targeted feedback: what went well, what slowed the response, and what to focus on next time.Over time, the radar chart fills out. Gaps become visible. Improvement becomes measurable. Engineering leaders can see exactly who is ready for independent on-call and where the team still has work to do.If your team is evaluating how to build a structured incident response training program, Uptime Labs is the fastest way to get started. There is no integration work, no production risk, and no setup required. Book a demo to see the full platform, or play a free drill to experience a simulation first-hand.
Incident Response Training: Deep Dives by Topic
This page is the starting point. For more details on each area of incident response training, read the full series:
- Incident Response Training for Junior Engineers — How to apply the four-stage training model specifically to engineers entering on-call rotations for the first time.
- Tabletop vs Live Incident Response: Which Does Your Team Actually Need? — A direct comparison of when tabletop exercises are sufficient and when your team needs live simulation.
- Incident Escalation Process: When, How, and Who Decides — A structured framework for escalation decisions, including when to escalate, who to involve, and how to avoid the most common mistakes.
- Reduce On-Call Burnout: A Practical Guide for Engineering Teams — Why unstructured on-call rotations burn out senior engineers, and what to do about it.
- Chaos Engineering Tools vs Incident Response Simulations — Where chaos engineering ends and human readiness training begins.
- What Is Chaos Engineering? — The fundamentals of chaos engineering: principles, how experiments work, and what it does and does not test.
- What Is an Incident Commander? — The role, responsibilities, and skills required to lead incident response effectively.
- What Is an Incident Handler? — What incident handlers do during a live incident and how the role differs from incident commander.
- Incident Response Runbook: Best Practices and Examples — What your runbooks should contain, how to keep them useful, and how to train against them.
- Enterprise Incident Response Plan: SRE Guide — How to build the process infrastructure that supports incident response at scale.
- The Best Incident Response Training Providers — A comparison of the leading incident response training providers for engineering teams.
- Best Cybersecurity Incident Response Training Platforms — A comparison focused on platforms for cybersecurity incident response training.
- 8 Best SRE Tools for Uptime and Reliability in 2026 — The observability and reliability tools your incident response training should integrate with.
FAQs: Incident Response Training
What is the difference between an incident response simulation and a tabletop exercise?
A tabletop is a discussion: participants talk through what they would do. A simulation places engineers inside a realistic environment where they use real tools, read real signals and make decisions under time pressure. Tabletops test plans. Simulations test people.
How is incident response simulation different from chaos engineering?
Chaos engineering tests whether systems degrade gracefully under fault conditions. Incident response simulation tests whether the people responding can diagnose, communicate, and make the right decisions under pressure. One tests infrastructure. The other tests the team.
How often should engineering teams run incident response drills?
A monthly cadence is a practical standard for most teams. Each drill should be targeted at a specific competency gap identified from previous sessions or from post-incident review findings. Drills that are not connected to real skill gaps produce familiarity, not improvement.
How do you measure whether incident response training is working?
Track competency scores for each engineer across specific skill categories (scoping, communication, incident command) over multiple sessions. Improvement is a consistent upward trend across sessions, not a single good drill. Time-based metrics like MTTR are useful outcome indicators, but do not tell you which specific capabilities to train next.
Is incident response training required for regulatory compliance?
For financial services organisations, yes. DORA requires financial entities to undertake digital operational resilience testing, including scenario-based exercises. The FCA's operational resilience framework in the UK requires firms to identify vulnerabilities through testing and conduct lessons-learnt exercises. For organisations outside financial services, regulatory requirements vary, but the business case for training exists independently of compliance.
Edward Page (Community Contributor)


